Ян Колле (Yann Collet), автор эталонной реализации алгоритма LZ4 (https://en.wikipedia.org/wiki/LZ4_%28compression_algori...
представил (http://fastcompression.blogspot.ru/2015/01/zstd-stronger-com... новый алгоритм сжатия Z-standard (https://github.com/Cyan4973/zstd) (ZSTD), сочетающий высокую скорость кодирования и декодирования с хорошей эффективностью сжатия. Алгоритм предназначен для использования в повседневном обиходе, но он не рассчитан на достижение рекордных скоростей, свойственных LZMA и ZPAQ, или максимальных уровней сжатия, обеспечиваемых в LZ4. По сравнению с обеспечивающими рекордные показатели системами предложенный алгоритм не является однобоким (скорость за счёт степени сжатия или степень сжатия за счёт скорости) и обеспечивает отличное соотношение скорости и эффективности сжатия. Библиотека с эталонной реализацией алгоритма распространяется (https://github.com/Cyan4973/zstd) под лицензией BSD.
<center>
<table style="border: 1px solid rgb(176, 177, 144); border-collapse: collapse; background: none repeat scroll 0% 0% rgb(221, 225, 194);" width="50%" border="1" cellpadding="2" cellspacing="0">
<thead>
<tr>
<th>Название</th>
<th>Степень сжатия</th>
<th>Скорость кодирования</th>
<th>Скорость декодирования</th>
</tr>
</thead>
<tbody>
<tr>
<td></td>
<td></td>
<td>MB/s</td>
<td>MB/s</td>
</tr>
<tr>
<td>zlib 1.2.8 -6 (http://www.zlib.net/)</td>
<td>3.099</td>
<td>18</td>
<td>275</td>
</tr>
<tr>
<td><strong>ZSTD</strong></td>
<td><strong>2.872</strong></td>
<td><strong>201</strong></td>
<td><strong>498</strong></td>
</tr>
<tr>
<td>zlib 1.2.8 -1 (http://www.zlib.net/)</td>
<td>2.730</td>
<td>58</td>
<td>250</td>
</tr>
<tr>
<td>LZ4 HC r127 (https://github.com/Cyan4973/lz4)</td>
<td>2.720</td>
<td>26</td>
<td>1720</td>
</tr>
<tr>
<td>QuickLZ 1.5.1b6</td>
<td>2.237</td>
<td>323</td>
<td>373</td>
</tr>
<tr>
<td>LZO 2.06</td>
<td>2.106</td>
<td>351</td>
<td>510</td>
</tr>
<tr>
<td>Snappy 1.1.0</td>
<td>2.091</td>
<td>238</td>
<td>964</td>
</tr>
<tr>
<td>LZ4 r127 (https://github.com/Cyan4973/lz4)</td>
<td>2.084</td>
<td>370</td>
<td>1590</td>
</tr>
<tr>
<td>LZF 3.6</td>
<td>2.077</td>
<td>220</td>
<td>502</td>
</tr>
</tbody>
</table>
</center>Скорость декодирования в ZSTD составляет примерно 500 Мб/сек на одном ядре процессора Intel Core i5-4300U (1.9 GHz) при скорости кодирования на уровне 200 Мб/сек, что позволяет использовать данный алгортим в сценариях по обработке данных в режиме реального времени. Кроме того, как и в LZ4, для ситуаций когда данные сжимаются один раз и многократно распаковываются в ZSTD предусмотрен режим форсированного сжатия, при котором достигается более высокий коэффициент сжатия за счёт увеличения времени упаковки.
Примечательной особенностью ZSTD также является возможность настройки потребления памяти, что позволяет использовать ZSTD на встраиваемых системах с небольшим размером ОЗУ или на серверах, одновременно обрабатывающих большое число сжатых потоков. Для декодирования требуется заполнение таблиц трансформации, размер который может быть настроен 2.5 до 20 Кб, а также выделение памяти под буфер с окном сжатия, который по умолчанию составляет 512 Кб, но может быть по желанию уменьшен до нескольких килобайт или увеличен до гигабайт (чем больше размер окна - тем выше уровень сжатия). В процессе сжатия данных дополнительно требуется выделение памяти под буфер сортировки, который по умолчанию составляет 128 Кб, но может быть произвольно уменьшен или увеличен.
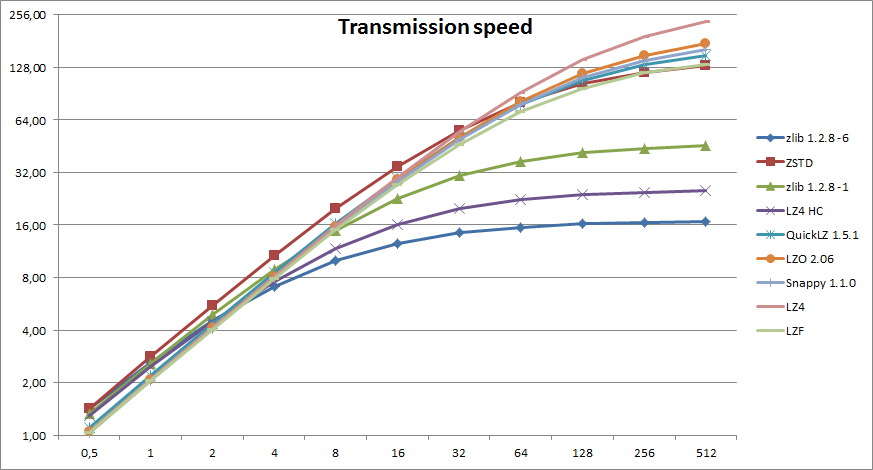
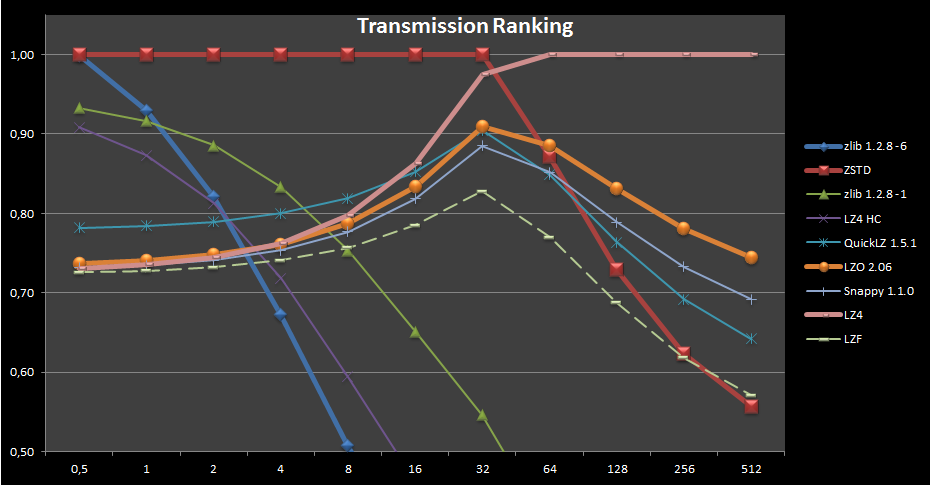
На приведённом ниже графике отражены параметры эксперимента по сжатию файла, передаче потока по сети и его распаковке на другом конце соединения. Первый рафик показывает соотношение времени выполнения операции (ось Y) к пропускной способность канала связи в Мб/сек (ось X). Второй график отличается тем, что вместо времени используется относительное ранжирование алгоритмов, при котором за 1 принят лучший для данной скорости результат, а остальные показатели показаны в процентном соотношении к нему.
<center><a href="http://2.bp.blogspot.com/-T_-mbRHqExM/VMKItdNShBI/AAAAAAAABH... src="http://www.opennet.me/opennews/pics_base/0_1422169920.png" style="border-style: solid; border-color: #e9ead6; border-width: 15px;max-width:100%;" title="" border=0></a></center>
<center><a href="http://2.bp.blogspot.com/-gE8B0wCfox4/VMKJFyaDO4I/AAAAAAAABH... src="http://www.opennet.me/opennews/pics_base/0_1422169956.png" style="border-style: solid; border-color: #e9ead6; border-width: 15px;max-width:100%;" title="" border=0></a></center>URL: http://fastcompression.blogspot.ru/2015/01/zstd-stronger-com...
Новость: http://www.opennet.me/opennews/art.shtml?num=41534
> он не рассчитан на достижение рекордных скоростей, свойственных LZMA и ZPAQ, или максимальных уровней сжатия, обеспечиваемых в LZ4Наоборот же.
Респект и уважуха автору, ждём поддержки в ядре и Btrfs.
А что ждать?
svn co http://lz4.googlecode.com/svn/trunk/ .
make -j 3
sudo make install
sudo modprobe lz4
sudo modprobe lz4hc
sudo update-initramfs -c -k `uname -r` -u
дописать в /etc/initramfs-tools lz4 и lz4hcgit clone git://git.kernel.org/pub/scm/linux/kernel/git/mason/btrfs-progs.git
patch -p1 < btrfs3.18.1-lz4.patch
патч взять отсюда https://github.com/xbianonpi/xbian-patches/tree/master/btrfs...
make -j 3
sudo make installgit clone https://github.com/pfactum/pf-kernel.git
patch -p1 < lz4.patch
патч взять отсюда https://github.com/xbianonpi/xbian-package-kernel/tree/maste...
make menuconfig паковать ядро lz4
make-kpkg clean
sudo make-kpkg -j 3 --initrd --append-to-version=+ kernel_image kernel_headers
sudo dpkg -i linux-header*.deb linux-kernel*.deb
А смысл этой возни? Там уже есть вполне сравнимый LZO, вот никто и не рвется особо имплементить еще 1 почти такой же алгоритм.
Почитай про checkinstall хотя бы, болезный.
То есть алгоритм не годится ни для одной конкретной задачи)
Вполне себе годится: на моих данных (логи в JSON-формате) жмёт по объёму так же как gzip -6, но при этом в 7.6 раза быстрее. По-моему очень достойный результат
А lz4 как при этом жмёт? Т.е. понятно, что размер сжатого файла будет несколько больше, но на сколько? и во сколько раз быстрее он сожмёт?
Судя по таблице вверху, lz4 сожмет не быстрее, а в несколько раз медленнее. И хуже. Но - разжиматься потом будет быстрее.
Есть lz4 hc, и есть просто lz4. Вглядись.
алгоритм, который среднячек во всём.
Предпочтёшь свербыстрый алгоритм, который почти не жмёт? Или отлично сжимающий, но результата ждать неделю на современном железе?
>Предпочтёшь свербыстрый алгоритм, который почти не жмёт? Или отлично сжимающий, но результата ждать неделю на современном железе?Жмем 7z или gz, а если сжимать не нужно - просто tar'им.
Но я слышал что есть люди которые верят в бога и пользуются винраром.
<сарказм>Все сжимаю в tar. Почему в тесте его нет?
> <сарказм>Все сжимаю в tar.Научите!</сарказм>
Ну если упаковывается множество мелких файлов, то можно сэкономить за счёт более рационального использования кластеров.
> Ну если упаковывается множество мелких файлов, то можно сэкономить за счёт более рационального использования кластеров.а сэкономишь аж 0,1%?
А теперь представь, что файлы по десятку байт и не неси фигню.
Если это не FAT какой-нибудь, то данные короткого файла лежат в метаданных, вместе с прочими атрибутами. Не занимает он ни одного кластера.
Минимум - inode + directory record.
Кстати, в ext4 inline data - это экспериментальная фича. В продакшне её нет.
А те, кто пользуются reiser3, используют notail. Быстрее и стабильней.
Это для наоборот. Опция даёт прирост в скорости в ущерб вместимости (- ~5%).
Кстати, Reiser4 умеет танцевать деревья для экономии дискового пространства.
"Dancing Tree" это как бы название структуры данных, а не "танец" каких-то других типов деревьев.
> "Dancing Tree" это как бы название структуры данных, а не "танец" каких-то
> других типов деревьев.спасибо, кэп. =)
А те, кто пользуются reiserfs - ищут грабли. начиная с риска угробить ФС к чертовой матери изаканчивая суровым падением скорости вследствеи фрагментации. Если, конечно, за последнюю пару лет что-то радикально не улучшилось, но не припомню такого.Если уж на то пошло - паковать хвосты умеет XFS. И, так как, судя по любви к reiserfs, вы живете в криокамере - информирую, что тормоза с мелкифи файлами на XFS уже с год как пофиксили.
>>А те, кто пользуются reiserfs - ищут грабли. начиная с риска угробить ФС к чертовой матери изаканчивая суровым падением скорости вследствеи фрагментации. Если, конечно, за последнюю пару лет что-то радикально не улучшилось, но не припомню такого.Атомарная структура Reiser4 позволяет избежать рисков что-то прое@бать при операциях с ФС. Ну а так, - в целом всё также стабильно как и в других ФС.
Фрагментация пока единственное неудобство, но думаю это решится в будущем.
>>Если уж на то пошло - паковать хвосты умеет XFS. И, так как, судя по любви к reiserfs, вы живете в криокамере - информирую, что тормоза с мелкифи файлами на XFS уже с год как пофиксили.
Ну и молодцы, что пофиксили. Я, живя в своей криокамере, этого не знал.:-\
P.S. Не фанат Reiser4, но уважаю.
Для начала - речь шла о reiserfs. Сейчас вы говорите о reiser4.Reiser4 нет в ядре (соответственно, она слабо протестирована) и, самое главное, её фактически некому поддерживать и развивать. Лично для меня на этом разговор закончен.
Что до reiserfs - опять-таки, ничего не решится, так как ей, собственно, никто не занимается.
Рейзера я и сам уважаю, но, с учетом развития с тех времён, когда он свои ФС создавал, я не вижу никакого смысла на них смотреть. Ну вот так не повезло им - были в своё время продвинутями и перспективными, да сплыли.
Хорошо, встанем тогда на том, что это хорошо когда у людей есть выбор, какой ФС пользоваться в GNU/Linux. =)Напоследок замечу, что VFS ядра запилена под ext*. К тому же, это один из самых динамичных кусков ядра Linux. И, наконец, третье - Linux перестал быть проектом энтузиастов. Теперь это проект корпораций с их легионами маркетологов и ручных кодеров.
С учётом этого, простым программистам, вроде Эдуарда Шишкина и небольшому сообществу энтузиастов, сформировавшемуся возле него, нелегко оставаться на гребне волны, программируя Just for fun. Но это не делает код и идеи Reiser4 устаревшими или неправильными.
В эпоху развития reiserfs v.3 Гансу Рейзеру удалось включить код в состав основной ветки ядра, тем самым обеспечив поддержку ФС Linux-сообществом. Но, во многом, благодаря наличию Namesys, маленькой, но компании. И уже как следствие включения в основную ветвь, со временем, код reiserfs v.3 стал отлаженным и полностью интегрированным.
Вот такие вот мои мысли на тему ReiserFS v.3/Reiser4. Спорить с ними совсем не обязательно, так как от этого они не перестанут быть моими. =)---
Честь имею, Ne01eX.
А тут и спорить не с чем. Сейчас, насколько я понимаю, в моде экстенты, но, вероятно, Рейзер сумел бы их со своей архитектурой подружить.Я на всё это смотрю с чисто практической точки зрения - использовать предпочтительно то, что, с одной стороны, показало свои возможности и ограничения, хорошо оттестировано и имеет приемлемые характеристики - а с другой имеет хорошую команду, которая бы правила ошибки и занималась развитием. На данный момент это Ext4 и XFS. Может, через годик btrfs подоспеет, хотя как по мне - это на порядок большее надругательство над линуксовой идеологией блочных устройств и ФС, чем то, что предлагал Рейзер. Но если покажет хороший практический результат - то и ладно.
> как по мне - это на порядок большее надругательство над линуксовой
> идеологией блочных устройств и ФС, чем то, что предлагал Рейзер.Есть небольшая разница. Btrfs-ники могут внятно показать что это дает. Ну там например возможность смешивать уровни райдов и переконфигурировать все это на лету. Без остановки системы и с плавной миграцией. А у рейзера только чисто теоретические возможности. Ну там чисто теоретически - можно например плагин для CoW сделать. Чисто практически - ну как бы пусть покажут это работающее со скоростью хоть того же бтрфс, тогда поверим. Ибо если плагином привинчивать CoW к обычной файлухе - это совсем не то же самое что проектировать файлуху сразу как CoW. Сложно самосвал в самолет перестраивать - конструкционные особенности разные. И тезис что а вот мы плагином все-таки так можем - ок, давайте готовый прототип и мы посмотрим на его летные качества.
Проснись, тормоз. В РСУБД экстенты в моде уже больше 30 лет - ты столько на свете не прожил.
> включения в основную ветвь, со временем, код reiserfs v.3 стал отлаженным
> и полностью интегрированным.Он так отлажен, что разгром тома fsck'ом при налете на "неправильное" дерево - known issue. С советом от разработчиков не хранить образа рейзеров на рейзере (ну то-есть, гудбай, виртуалки!). Ну его нафиг такую стабильность с такими known issues, Мэйсон и его шака как-то поадекватнее к эксплуатационщикам.
> Кстати, в ext4 inline data - это экспериментальная фича. В продакшне её нет.А в btrfs уже есть. И сжатие.
>> Кстати, в ext4 inline data - это экспериментальная фича. В продакшне её нет.
> А в btrfs уже есть. И сжатие.В ZFS это есть уже лет 8.
> В ZFS это есть уже лет 8.А системный кеш вместо собственного выноса там уже используется?
>> В ZFS это есть уже лет 8.
> А системный кеш вместо собственного выноса там уже используется?Посчитай сам:
last pid: 49014; load averages: 0.30, 0.26, 0.25 up 0+06:04:38 01:12:48
63 processes: 1 running, 62 sleeping
CPU: 1.4% user, 0.0% nice, 0.6% system, 0.0% interrupt, 98.1% idle
Mem: 381M Active, 1414M Inact, 3275M Wired, 120K Cache, 6839M Free
ARC: 2241M Total, 681M MFU, 1215M MRU, 1216K Anon, 25M Header, 320M Other
Swap:Всё ОЗУ 12ГБ.
Не используется. В топку.
Даже если результат меньше оригинала на два бита, то это уже сжатие.
> <сарказм>Все сжимаю в tar. Почему в тесте его нет?потому что он архиватор
ждем в 7зип ?
А зачем он там, если lzma жмет эффективней при сравнимой скорости?
А можно подробнее про большую скорость lzma?
https://github.com/mcmilk/7-Zip-zstd
> Первый рафик показывает соотношение времени выполнения операции (ось Y) к пропускной способность канала связи в Мб/сек (ось X).Или по оси Y не время, а скорость, или получается что чем выше пропускная способность канала, тем дольше длится операция...
Хотелось бы ZSTD в TokuDB увидеть... Самое оно.
> Хотелось бы ZSTD в TokuDB увидеть... Самое оно.Хотелось? Возьми и запили. Делов-то.
А в MySQL до сих пор только zlib, только в innodb и, по сути, размер всё равно больше, чем у несжатой myisam...
> А в MySQL до сих пор только zlib, только в innodb и,
> по сути, размер всё равно больше, чем у несжатой myisam...zlib в innodb не нужен, в innodb структура организована таким образом, что сжатие делает её совершенно неповоротливой при записи - она вся расчитана на страницы фиксированной и неизменной длины. Ну а myisam вообще пора запретить, как зло.
Ага, и использовать двиг, который занимает в 7 раз больше места? ( http://www.percona.com/forums/questions-discussions/mysql-an... ). Боже упаси. Я не проверял, но что-то верится с трудом что innodb при таком оверхеде может быть быстрее myisam.
> Ага, и использовать двиг, который занимает в 7 раз больше места? (Когда в первый раз попробуете "починить" (а падают myisam'ы при некорректной остановке mysqld влёт) таблицу размером хотя бы гиг в 20 - перескочите на innodb/tokudb быстро, и без шелеста :) Плюс нет поддержки транзакций совершенно, плюс полная блокировка при записи...
Вообще таблица myisam в 50 Gb + 40 Gb индекса, доставшаяся от предшественника, в несжатом innodb заняла 75 - т.е. никаких "в 7 раз" не наблюдается. TokuDB+lzma уфигачил вместе с индексом в 25 гиг, при этом производительность как чтения, так и записи только выросли (да и нагрузка на CPU сильно не подскочила) :)
Я рад за вас, у меня таблицы при переводе на innodb разрастаются в 5 раз. Лично я по этому параметру вижу регресс, myisam по тестам оказывается гораздо быстрее. Еслиб еще к этому двигу прикрутили сжатие и построчную блокировку, - myisam бы обходил innodb на порядки.
Транзакции, кстати, далеко не всем нужны.
Порекомендуйте идеальную СУБД?
Не успел я написать слово "Oracle", как у моего комментария уже был минус :)
> Порекомендуйте идеальную СУБД?Порекомендуйте идеальный автомобиль.
> Порекомендуйте идеальный автомобиль.Летающий DeLorian :).
{kind=link}
{kind=link}
{kind=link}
{kind=link}