Ingo Molnar, чтобы доказать повышение эффективности работы нового планировщика задач (CFS), представил (http://kerneltrap.org/Linux/Measuring_Process_Scheduler_Perf...) результаты сравнения производительности Linux ядер 2.6.23 и 2.6.22.9 (график (http://people.redhat.com/mingo/misc/sysbench.jpg)). Тестирование проводилось при помощи утилиты sysbench (http://sysbench.sourceforge.net/) совместно с СУБД MySQL 5.0.45.
Днем позже, Ingo опубликовал результаты (http://people.redhat.com/mingo/misc/sysbench-sched-devel.jpg), включив в сравнение три дополнительных конфигурации ядра 2.6.23 с подкорректированными параметрами планировщика.URL: http://kerneltrap.org/Linux/Measuring_Process_Scheduler_Perf...
Новость: http://www.opennet.me/opennews/art.shtml?num=12398
ну, красота :)что сказать... вещь
и вещь отданная под GPL'ем...
было бы любопытно взглянуть на тесты .23 ядра со срезами BSDшных высот
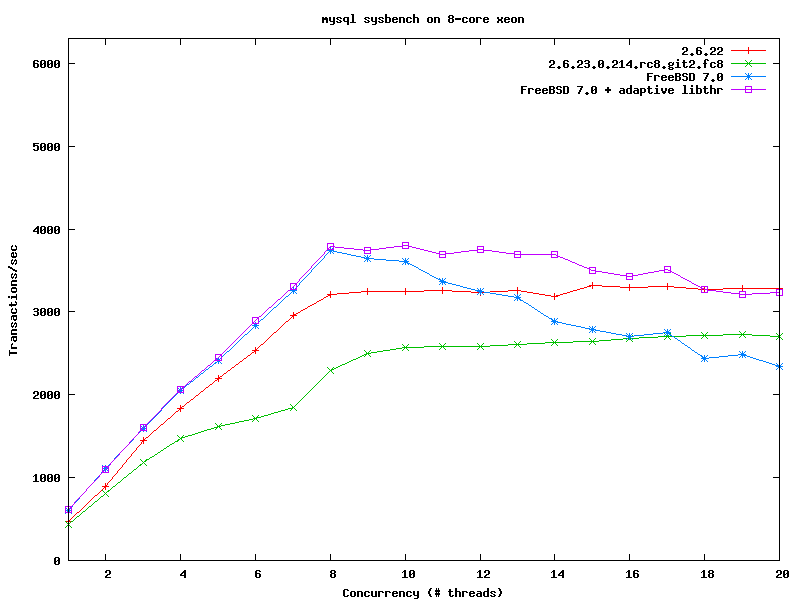
http://people.freebsd.org/~kris/scaling/http://people.freebsd.org/~kris/scaling/linux-mysql.png
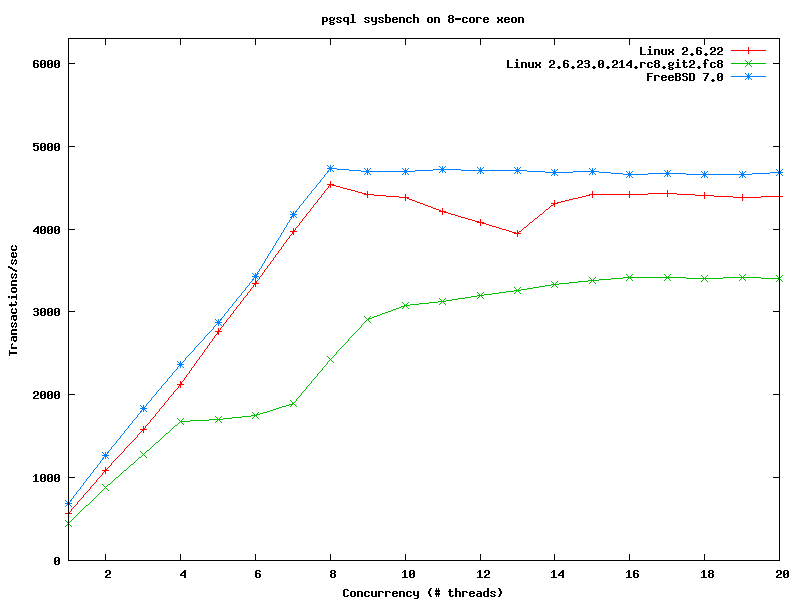
http://people.freebsd.org/~kris/scaling/linux-pgsql.png
типа так?
для начала неплохо
но вобщем-то желательно не release candidat рассматривать
и в ванильном виде (не знаю чего там Федора подмешала)
Ага только вот там про огрехи gnu glibc malloc промолчали. Несколькими новостями ниже есть сравнение ядра linux с tcalloc. Там график ровнее.
А трехкратное падение производительности для одного клиента это типа нормально? Зато OMFG, теперь мы на 20% меньше тупим на десятке клиентов.
посмотри начало графиков
в первой точке, которая соответствует 1 клиенту, транзакций в .23 меньше в 3 раза
На графиках количество транзакций в секунду не от нуля начинается, а от 400.
Так что падение не в три раза, а где-то на 20 процентов (что тоже не очень радует).
блин, который раз накалываюсь на этом :)
да расслабьтесьсистеме с один запросом в единицу времени пофик производительность ЗАЧАСТУЮ
Интересны именно паралельные запросы.
Так что даже если пере Инго стоял выбор - он его сделал верно.
Все уроды, я the best !!!Ладно, по делу:
> ... and i'm definitely interested in more
> feedback about this:asmlinkage long sys_time(time_t __user * tloc)
{
- time_t i;
- struct timespec tv;
-
- getnstimeofday(&tv);
- i = tv.tv_sec;
+ time_t i = get_seconds();
Хотя, может на VAX или на ARM get_seconds() не работает???
>Хотя, может на VAX или на ARM get_seconds() не работает???Эй, мокрый куриц, а на мипс?
Господа, а какой подскажет какой утилиткой такие графички рисуются? Неужтно gnuplot'ом?
Да ты так не пугайся gnuplot_a, часика три помучаешся, потом понравиться!
А есть подобные графики для Соляриса?
а кто знает, почему в новое ядро не включают tcmalloc, вместо обычного malloc'а?
Это не проблема ядра. Это проблема glibc
точно, глупость сказал, сорри.
не знаете, почему в glibc его не включают?
У него есть свои недостатки.
Например (пока) он не возвращает память операционной системе.Как стандартный аллокатор назначения он не годится.
Многопоточные программы, постоянно выделяющие/освобождающие память легко могут его использовать вместо стандартного. Остальные программы нечего ломать :)
Кроме прочего, в 2.6.23 добавились усовершенствования производительности в read ahead, reiserfs и XFS. Тоже, ИМХО, немаловажные штучки в плане быстродействия всей системы. Хотя в контексте этого теста они, конечно, не так чувствуются.
Не успели обругать.... как 2.6.23.1 надворе. :)libata: sata_mv: more S/G fixes
* corruption fix: we only want the lower 16 bits of length (0 == 64kb)* ditto: the upper layer sets max-phys-segments to LIBATA_MAX_PRD, so we must reset it to own
hw-specific length.* delete unused mv_fill_sg() return value.
может кучкуются чтобы второй проц ничем не занимать?
Vanila 2.6.23pavel@toshka:~> uname -a
Linux toshka 2.6.23 #3 SMP PREEMPT Thu Oct 11 21:59:37 MSD 2007 x86_64 x86_64 x86_64 GNU/Linuxpavel@toshka:~> cat /proc/interrupts
CPU0 CPU1
0: 101550 0 IO-APIC-edge timer
1: 9 108 IO-APIC-edge i8042
8: 1 0 IO-APIC-edge rtc
9: 95 59 IO-APIC-fasteoi acpi
12: 132 0 IO-APIC-edge i8042
14: 2507 4513 IO-APIC-edge libata
15: 178 769 IO-APIC-edge libata
16: 1 4190 IO-APIC-fasteoi uhci_hcd:usb4, nvidia
18: 31 801 IO-APIC-fasteoi uhci_hcd:usb3, tifm_7xx1, sdhci:slot0
19: 0 0 IO-APIC-fasteoi uhci_hcd:usb2
20: 9 353 IO-APIC-fasteoi eth0
22: 627 0 IO-APIC-fasteoi HDA Intel
23: 60 0 IO-APIC-fasteoi uhci_hcd:usb1, ehci_hcd:usb5
NMI: 0 0
LOC: 101436 100914
ERR: 0Vanila (2.6.23) + Ingo Monlar RT Patch (2.6.23-rt1)
pavel@toshka:~> uname -a
Linux toshka 2.6.23-rt1 #5 SMP PREEMPT RT Fri Oct 12 23:45:03 MSD 2007 x86_64 x86_64 x86_64 GNU/Linuxpavel@toshka:~> cat /proc/interrupts
CPU0 CPU1
0: 116 0 IO-APIC-edge timer
1: 45 0 IO-APIC-edge i8042
8: 1 0 IO-APIC-edge rtc
9: 223 0 IO-APIC-fasteoi acpi
12: 135 0 IO-APIC-edge i8042
14: 21295 0 IO-APIC-edge libata
15: 2069 0 IO-APIC-edge libata
16: 12560 1 IO-APIC-fasteoi uhci_hcd:usb5, nvidia
18: 3618 0 IO-APIC-fasteoi uhci_hcd:usb4, tifm_7xx1
19: 0 0 IO-APIC-fasteoi uhci_hcd:usb3
20: 1906 0 IO-APIC-fasteoi eth0
22: 836 0 IO-APIC-fasteoi HDA Intel
23: 31 0 IO-APIC-fasteoi ehci_hcd:usb1, uhci_hcd:usb2
NMI: 0 0
LOC: 109061 110664
ERR: 0
pavel@toshka:~> cat /proc/cpuinfo | grep "model name"
model name : Intel(R) Core(TM)2 CPU T7400 @ 2.16GHz
model name : Intel(R) Core(TM)2 CPU T7400 @ 2.16GHz
Какие мысли? Почему все прерывания на первом ядре кучкуются?
ИМХОв не-RT ядре прерывания нужно обрабатывать сразу, по мере их появления.
За сим, любой свободный проц чудно подходит для этого.А в ядре, где для прерываний свои очереди выполнения имеют - их можно и отложить, выпонив на одном проце. Именно на одном, видать, по кешу выгодно.
{kind=link}
{kind=link}
{kind=link}