Kris Kennaway провел (http://people.freebsd.org/~kris/scaling/ebizzy.html) серию сравнений производительности аллокаторов памяти FreeBSD (тестировалась ветка 8.0) и Fedora 8 Linux (ядро 2.6.24, glibc 2.7). Сравнивалась производительность на тесте ebizzy (http://sourceforge.net/projects/ebizzy/), симулирующем работу с памятью характерную для баз данных. В качестве аппаратной платформы был использован 8-ядерный сервер на базе Intel Xeon.
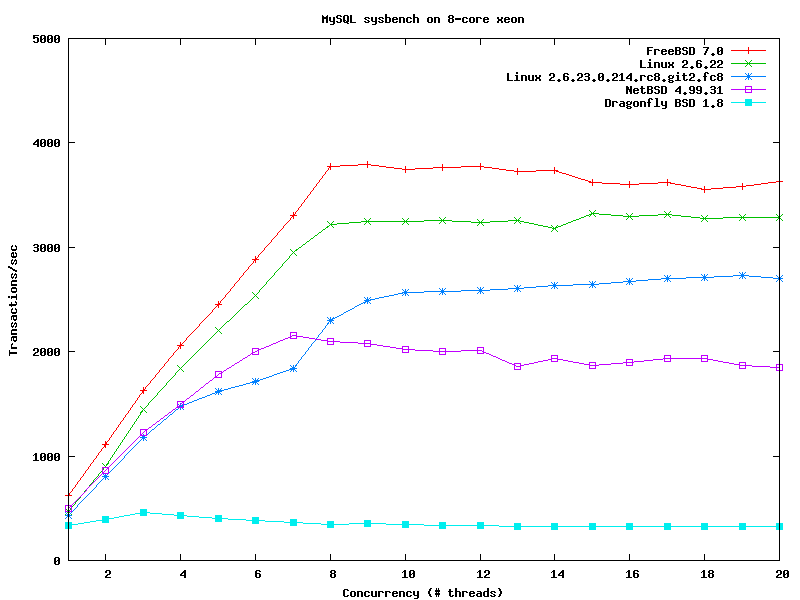
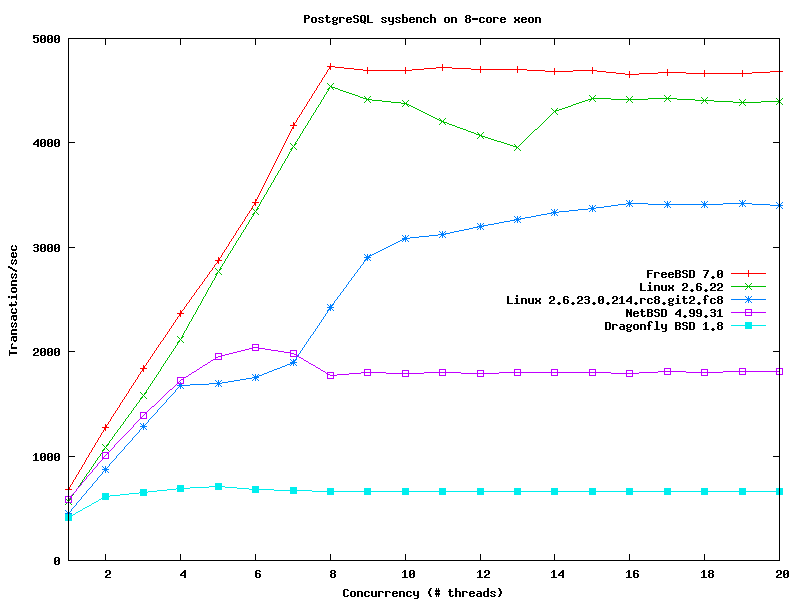
Кроме того Kris провел исследование (http://people.freebsd.org/~kris/scaling/dfly.html) производительности DragonFlyBSD 1.12 в сравнении с FreeBSD 4.11/7.0 и повторил тестирование (http://people.freebsd.org/~kris/scaling/mysql.html) производительности СУБД, при помощи утилиты sysbench (график тестирования mysql (http://people.freebsd.org/~kris/scaling/os-mysql.png), график тестирования PostgreSQL (http://people.freebsd.org/~kris/scaling/os-pgsql.png)). Общие выводы отражены в документе "Notes on SMP performance on FreeBSD (http://people.freebsd.org/~kris/scaling/smp.html)".URL: http://people.freebsd.org/~kris/scaling/ebizzy.html
Новость: http://www.opennet.me/opennews/art.shtml?num=14649
тоесть freebsd 8 круче всех?, так и запишем
Есть хоть какие-то шансы, что во фре появится быстрая FS? Без этого пусть хоть в 2 раза быстрее аллокатор будет, в реальной жизни FreeBSD будет в аутсайдерах.ZFS ещё совсем сырое и по дизайну мегатормозное. GJOURNAL ещё сырое. Что остается? UFS2+SU? Ugh..... Вчера вычитал в рассылке freebsd-stable@. Просто офигел... Для проверки террабайтной UFS2 fsck надо гиг ОЗУ, причём в kernelspace, соответственно, надо /boot/loader.conf править и перегружаться. При этом FS проверяется больше часа.
Дальше вылез Мэтт Диллон и добавил, что при количестве inode-ов в 40млн, на архитектуре i386 даже теоретически не хватит памяти проверить такую FS. А Oliver Fromme (тоже матерый бздун) предложил вытащить из соседнего сервака памяти и воткнуть в тот, что всё никак не может проfsckаться.... Короче, enterprise просто мощный... Я читал и плакал...Хотя совсем не так давно я фанател по этой ОС... %-[~~~
Кстати, используется 32-битный режим почему-то. Просто тупо молча. Наверное чтобы не говорить лишний раз, что у FreeBSD с её одной единственной веткой портов на ВСЕ семейства с 64-битами всё очень грустно.Короче, напрягают меня такие "честные сравнения" со стороны Кенни. Тем более, что у Ника Пиггина даже в предложенных Кеннавеем условиях линукс получается быстрее... С чего бы вдруг....
Что за бред про 32-битный режим? Все на 64бит, никаких проблем.
Что за бред про одну ветку? А сколько вы хотели? По ветке на архитектуру? Сможете объяснить зачем? Broken на amd64 вообще-то всего 32 порта.
Про тормозной и сырой ZFS - тоже посмеялся. 2 месяца в продакшне (пока на HA кластере, разумеется) - ни одной проблемы. Такой стабильной ФС я, пожалуй, еще не видел. Со скоростью тоже все ok - с большими файлами и raidz - 90% от теоретического максимума (пропускная способность дисков). На мелких файлах особо не мерял, но по крайней мере операции с деревом портов раз в 5 быстрее UFS.
fsck мне никогда не был нужен. Хотя с ним потенциальная проблема есть, согласен. Только не поверю что ему нужна ядерная память.В общем, все как всегда. Руки.
>Что за бред про 32-битный режим? Все на 64бит, никаких проблем.Что "всё"? Почему тестирование Кенни провёл в заскорузлых 32 битах?
>Что за бред про одну ветку? А сколько вы хотели? По ветке на архитектуру? Сможете объяснить зачем? Broken на amd64 вообще-то всего 32 порта.
Откуда дрова? Ни в жисть не поверю, после всего прочитанного в разных листах, что из 18 тысяч портов только 32 штуки в 64битах не работают. ФАНТАСТИКА! Во фре намного больше просто BROKEN портов, не говоря о специфике. Ещё скажите, что на других архитектурах тоже все 18 тыщ портов отлично работают... :)
>Про тормозной и сырой ZFS - тоже посмеялся. 2 месяца в продакшне
>(пока на HA кластере, разумеется) - ни одной проблемы. Такой стабильной
>ФС я, пожалуй, еще не видел. Со скоростью тоже все ok
>- с большими файлами и raidz - 90% от теоретического максимума
>(пропускная способность дисков). На мелких файлах особо не мерял, но по
>крайней мере операции с деревом портов раз в 5 быстрее UFS.Да, все баги, которые постоянно вылазят у подписчиков freebsd-stable@ твоих прямых рук испугались и спрятались...
>fsck мне никогда не был нужен. Хотя с ним потенциальная проблема есть,
>согласен. Только не поверю что ему нужна ядерная память.
>В общем, все как всегда. Руки.Не верь дальше. Как всегда - фанаты упёрты.
>Да, все баги, которые постоянно вылазят у подписчиков freebsd-stable@ твоих прямых рук
>испугались и спрятались...Возможно это касается ветки Карент, но в Стабл никаких проблем в пределах означеной функциональности в обычной эксплуатации не замечал.
>[оверквотинг удален]
>
>Что "всё"? Почему тестирование Кенни провёл в заскорузлых 32 битах?
>
>>Что за бред про одну ветку? А сколько вы хотели? По ветке на архитектуру? Сможете >>объяснить зачем? Broken на amd64 вообще-то всего 32 порта.
>
>Откуда дрова? Ни в жисть не поверю, после всего прочитанного в разных
>листах, что из 18 тысяч портов только 32 штуки в 64битах
>не работают. ФАНТАСТИКА! Во фре намного больше просто BROKEN портов, не
>говоря о специфике. Ещё скажите, что на других архитектурах тоже все
>18 тыщ портов отлично работают... :)Зачем верить ну есть же сухая стистика:
http://portsmon.freebsd.org/portserrcounts.py?buildenv=amd64
http://pointyhat.freebsd.org/errorlogs/packagestats.html
>>Что за бред про 32-битный режим? Все на 64бит, никаких проблем.
>Что "всё"? Почему тестирование Кенни провёл в заскорузлых 32 битах?Это не в курсе, у него спросите.
>>Что за бред про одну ветку? А сколько вы хотели? По ветке на архитектуру? Сможете объяснить зачем? Broken на amd64 вообще-то всего 32 порта.
>Откуда дрова? Ни в жисть не поверю, после всего прочитанного в разных
>листах, что из 18 тысяч портов только 32 штуки в 64битах
>не работают. ФАНТАСТИКА! Во фре намного больше просто BROKEN портов, не
>говоря о специфике. Ещё скажите, что на других архитектурах тоже все
>18 тыщ портов отлично работают... :)У меня ни на десктопе, ни на ноуте, ни на серверах каких-то 64bit-specific проблем не было. Дрова из grep BROKEN по Makefiles | grep amd64. 36. Минус четыре штуки, где amd4 в другом контексте. Это официально BROKEN. Неофициально сломанные вылезли бы при сборке на кластере, ссылки вам дали. Лишних сломанных там, как видите, нет. Там была еще красивая статистика в виде гистограмм, сами ищите.
>Да, все баги, которые постоянно вылазят у подписчиков freebsd-stable@ твоих прямых рук
>испугались и спрятались...Подписаться что-ли. Видимо, веселое чтиво.
>Не верь дальше. Как всегда - фанаты упёрты.
Если появится что-то более подходящее под мои нужды, чем фря, я буду использовать именно это. Меня больше беспокоят неадекватные личности, которые не просто любят поорать, как у них ничего не работает, но и подоказывать, что у остальных оказывается тоже все сломано. Порты не собираются, ZFS сырой и тормозной, ага. Не люблю троллей.
гг суровая реальность :)
Если у вас есть разделы по Терабайту, то строго рекомендуется использовать журнализированную ФС. И кто вам сказал, что она "сырая"? Надо было хотя бы ознакомиться с возможностями и ограничениями различных ф/с перед тем, как терабайтный разделы пилить, а не рассуждать тут о том, что вот система какая плохая, я о неё нихрена не знаю, делаю абы чего, а она ещё работать отказывается, как я себе напридумывал.П.С: Господа пионеры, бросай привычку вякнуть абы чего, лишь бы голос подать.
Если у вас разделы по терабайту, то строго рекомендуется использовать нормальную ОС. Я правильно понял? :-DПотому как UFS2 якобы и больше поддерживает, но КАК? И в документации, кстати, ни слова про то, что оно будет fsck-аться 3 часа и что сам fsck будет валиться и жрать память как свинья помои. GJOURNAL только вышло из статуса беты, zfs ещё не вышло. Тот кто СЕЙЧАС использует FreeBSD по всем признакам пионер. А вовсе не те, кто ругает бзду...
зачет :)
>зачет :)Нет, _Nick_, не зачёт. Пионер лепит херню. Так что слюни пускать не советую.
>Нет, _Nick_, не зачёт. Пионер лепит херню. Так что слюни пускать не
>советую.ну, слюна уже пущена :))
PS с сеня сам переползаю с JFS на ext4. Во де красота.
И online resize (как в JFS), но и offline shrinking (чего ТАК не хватало
в JFS), вагон рулей тюнинга, обратная совместимость с ext3 (пока на включишь
новые фичи).
>PS с сеня сам переползаю с JFS на ext4. Во де красота.
>
>И online resize (как в JFS), но и offline shrinking (чего ТАК
>не хватало
>в JFS), вагон рулей тюнинга, обратная совместимость с ext3 (пока на включишь
>
>новые фичи).offline shrinking - это де опечатка?
если online shrinking, то в jfs2 вполне себе есть
>offline shrinking - это де опечатка?никаких опечаток.
Хоть какой shrinking. Потому как в JFS Линуховом его нету ваще.
>если online shrinking, то в jfs2 вполне себе естьхотя я и сам нагуглил, что в AIX в JFS2 есть shrinking.
Но пасиба, я лучше пешком постою :)
> будет fsck-аться 3 часасократи кол-во inode'ов
newfs(8)
-i bytes
Specify the density of inodes in the file system. The default is
to create an inode for every (4 * frag-size) bytes of data space.
If fewer inodes are desired, a larger number should be used; to
create more inodes a smaller number should be given. One inode
is required for each distinct file, so this value effectively
specifies the average file size on the file system.
>Тот кто СЕЙЧАС использует FreeBSD по всем признакам пионер. А вовсе не те, кто ругает бзду...Так, а зачем тогда ты её используешь? Используй Linux, лично меня в нём всё устраивает.
>Так, а зачем тогда ты её используешь? Используй Linux, лично меня в
>нём всё устраивает.А какие в линуксе есть встроенные механизмы защиты данных при нештатной перезагрузке? Я без иронии, просто не в курсе многих решений. И как Линукс обрабатывает терабайтные разделы с десятками миллионов файлов?
>А какие в линуксе есть встроенные механизмы защиты данных при нештатной перезагрузке?
>Я без иронии, просто не в курсе многих решений.журнал.
если какой коммит не закончится полностью (что большая редкость, как ты понимаешь),
то fsck пойдет полную проверку делать. Иначе (считай 99% сбоев) - просто откатит журнал.
Секунды.>И как Линукс обрабатывает терабайтные разделы с десятками миллионов файлов?
Да вот так же и обрабатывает :)
Есть пара толстых стораджей с 4Тб рейдами.
Ну, пара лет уже как, но ни разу полный чек не потребовалсо.
Обычная ext3.
А почему журнал по-умолчанию отключен?
Не потому ли, что он так тормозит работу ФС, что это можно терпеть только на столе?
А файлы размером больше 4Гб ext поддерживает? Как давно?
А лепить по 50 патчей в сутки, исправляющих кривизну "стабильных" релизов - это нормально?кернел.орг - это кунсткамера анекдотов. Это моё IMHO, разумеется, IMHO человека, который юзает BSD с 1987 года (Demos из курчатовсксого - это клон БЗДи), и почитывал код из всех существующих клонов юникса. Я называю кернел.орг детским садом, клубом юных техников, а ребятишки вроде тебя переехали на африканскую убунту с маздая совсем недавно, а то, что ты пищешь, вычитали на своих ребяческих форумах. Завязывай блестеть памперсами, повзрослеешь - будет стыдно.
Хотя БЗДя меня уже давно не устраивает во многих местах, это пока лучшее, что есть на стол и в стойку. Ещё бы вернулись бы к корням и подчерпнули бы побольше от План9 - цены бы им не было. Ну и с микроядерностью тоже хорошо бы подружится, меня USB-девайсы раз в неделю стабильно перезагружают.
>А почему журнал по-умолчанию отключен?
>Не потому ли, что он так тормозит работу ФС, что это можно
>терпеть только на столе?
>А файлы размером больше 4Гб ext поддерживает? Как давно?# ls -l my_file
-rw-r--r-- 1 root root 1048577048576 Mar 11 05:40 my_file
>А лепить по 50 патчей в сутки, исправляющих кривизну "стабильных" релизов -
>это нормально?конечно ж нет.
Поэтому этого и не просиходит :)
>Хотя БЗДя меня уже давно не устраивает во многих местах, это пока
>лучшее, что есть на стол и в стойку
>....
>меня USB-девайсы раз в неделю стабильно перезагружают.no comments
>А почему журнал по-умолчанию отключен? Не потому ли, что он так тормозит работу ФС,
>что это можно терпеть только на столе?Долго думали такую несусветную глупость сообразить? Нешто будете мерять UFS2 против ext3, не говорю про xfs?
>А файлы размером больше 4Гб ext поддерживает? Как давно?
Проснитесь, Андрей, всячески предлагаю -- проснитесь.
ext я вот десять лет тому уже не застал, а сейчас за окном -- ext3 и приближается ext4. И то с xfs просто не помню, что такое "лимит на размер файла". У меня таких стораджей-то нет.
>А лепить по 50 патчей в сутки, исправляющих кривизну "стабильных" релизов -
>это нормально?Да, это нормально: если кривизна обнаружена, то чем выше доступность исправлений, тем больше выбора у тех, кого она потенциально затрагивает.
Вы хотите сказать, что нормально -- это сидеть на багах?
>Это моё IMHO, разумеется, IMHO человека, который юзает BSD с 1987 года
>(Demos из курчатовсксого - это клон БЗДи), и почитывал код из всех существующих
>клонов юникса.Что, и Coherent зацепили? Сколько раз объяснять -- старость порой приходит одна, не тем мерить стоит.
>Я называю кернел.орг детским садом, клубом юных техников
*sigh*
Припоминая Ваше резюме -- боюсь, с ним и в такой детсад бы не приняли...
>Завязывай блестеть памперсами, повзрослеешь - будет стыдно.
Давайте на брудершафт это стикером к монитору? :)
>Хотя БЗДя меня уже давно не устраивает во многих местах, это пока
>лучшее, что есть на стол и в стойку. Ещё бы вернулись
>бы к корням и подчерпнули бы побольше от План9 - цены
>бы им не было. Ну и с микроядерностью тоже хорошо бы
>подружится, меня USB-девайсы раз в неделю стабильно перезагружают.Офигеть.
Ну что ж, пусть продолжает устраивать. Другим-то работать надо.
Ну для начала в большинстве Linux'овых ФС есть журналирование. Во-вторых часть данных ты потеряешь в любом случае, и важно не это, а важно то, чтобы была согласованость между метаданными и непотеряными данными в ФС (тафталогия блин). Лично я знаю всего лишь три модели, позволяющие добиться этого, опробованые в промышленых масштабах: журналирование (ext3-4, xfs и т. д.), мягкие обновления (UFS2), COW (ZFS). У SoftUpdates есть два больших преимущества: простота реализации и высокая производительность, в идеале как при ассинхронной записи, но как выяснилось очень сложно реализовать fsck, т.к. надо прошуршать почти всю ФС. А fsck при журналировании пробегает лишь по относительно небольшому журналу и откатывает незавершённые действия, зато более сложная реализация и при каждой операции меняющей содержимое стабильного хранилища приходится синхронно писать лог в журнал. COW просто копирует данные при записи в другое место, а затем атомарно обновляет метаданные - отсюда сложность быстрой реализации, но ФС находится всегда в согласованом состоянии. Есть и ещё один метод - синхронная запись, но это жутко медленно.
Короче, я не программист и не разработчик ФС, поэтому мои познания поверхностны и возможно неправильны.
Если есть желание узнать об этих механизмах больше смотри книгу "Маршалл Кирк МакКузик FreBSD архитетура и реализация" и FreeBSD handbook - здесь достаточно доступно описано про SoftUpdates и причины использования именно этой технологии. Google поможет найти про журналирование и COW (смотри документацию по ZFS). Также, если интересно погляди про BLUFFS - реализация журналирования для UFS на уровне ФС, на одном из прошедших BSDCan была презентация этого проекта, вроде как обещают включить в FreeBSD 8.Для себя я решил, что если мне надо работать с большим хранилищем >2TB, то остаётся только два варианта, либо журналирование - Linux, либо COW - ZFS + Solaris. FreeBSD пока можно не рассматривать, т.к. у Soft Updates проблема с fsck, а ZFS+FreeBSD или FreeBSD + gjournal пока экспериментальные, хотя возможно к 7.1 или к 7.2 их уже можно будет считать достаточно стабильными. Собственно я выбрал Linux, т.к имею с ним опыт работы.
> COW просто копирует данные при записи в другое место, а затем атомарно обновляет метаданные - отсюда сложность быстрой реализации, но ФС находится всегда в согласованом состоянии.COW в ZFS не копирует неизмененные блоки, а только меняет метаданные на измененные блоки. И производительность у ZFS страдает еще от подсчитывания checksum'ов на данные и метаданные, но все это только при записи, т.к. при чтении эта ФС быстрее чем UFS.
> ZFS+FreeBSD или FreeBSD + gjournal пока экспериментальные, хотя возможно к 7.1 или к 7.2
ZFS скорее всего еще будет долго экспериментальной. По крайней мере пока не отладят проблемы с памятью до автотюнинга (а не ручного) и не включат поддержку ACL. Но даже сейчас эту ФС уже можно использовать в продакшне (и используют), если руки не совсем кривые или задачи не слишком специфичные.
>COW в ZFS не копирует неизмененные блоки, а только меняет метаданные на
>измененные блоки. И производительность у ZFS страдает еще от подсчитывания checksum'ов
>на данные и метаданные, но все это только при записи, т.к.
>при чтении эта ФС быстрее чем UFS.
>Ну ещё бы она копировала то, что уже и так на диске. Чтение не составляет проблемы для сохранения данных, а скорость ZFS на чтении как мне видится больше обусловлена грамотным кэшированием.
>А какие в линуксе есть встроенные механизмы защиты данных при нештатной перезагрузке?Журнал, как обычно.
>И как Линукс обрабатывает терабайтные разделы с десятками миллионов файлов?
Нормально себе отрабатывает. И многотерабайтные с непомнюсколькофайлов -- тоже. Причём очень давно: в 2003 вовсю стораджи со специализированным дистрибутивом на базе ALT Linux с XFS и управлением томами разбирали :)
>Я правильно понял? :-DНе знаю. Видно, что с пониманием у тебя по жизни не лады.
>Есть хоть какие-то шансы, что во фре появится быстрая FS? Без этого
>пусть хоть в 2 раза быстрее аллокатор будет, в реальной жизни
>FreeBSD будет в аутсайдерах.реальная жизнь это не только PC-серверы, а еще и embedded хотя бы. Не везде нужна такая FS как zfs.
>ZFS ещё совсем сырое и по дизайну мегатормозное.
сравни версию во фре и в солярке. Но тормозит скорее всего у тебя интерфейс между стулом и компьютером.
> UFS2+SU?
нет, просто ufs2 на gmirror или gstripe. softupdates - это вообще отдельная "веселая" песня.
> при количестве inode-ов в 40млн
а зачем тебе столько inode'ов? язык чесать?
>реальная жизнь это не только PC-серверы, а еще и embedded хотя бы.
>Не везде нужна такая FS как zfs.Во-во.На этот случай нужна простая и легкая FS и желательно быстрая.UFS тут топор, EXT2\3 тоже топор, но хотя-бы с поплавком (для лучшего плавания по бурным рекам).Зато есть еще всякие JFS и XFS которые местами интересны.Для embedded есть всякие SquashFS, JFFS и т.п. файловые системы.
>сравни версию во фре и в солярке. Но тормозит скорее всего у
>тебя интерфейс между стулом и компьютером.Хороший ответ, ага.От этого у вопрошавшего все заработало лучше, добавилась поддержка новых ФС, и вообще солнышко стало ярче, травка зеленее ну и все такое... =)
>> при количестве inode-ов в 40млн
>а зачем тебе столько inode'ов? язык чесать?А вы давно на емкость современных HDD смотрели?Далеко не любой файл весит по 600 мегабайт, а?Ну в общем стандартные ответы из рубрики "свое ... не пахнет" :\
>А вы давно на емкость современных HDD смотрели?Далеко не любой файл весит
>по 600 мегабайт, а?Ну в общем стандартные ответы из рубрики "свое
>... не пахнет" :\Что ты будешь делать, если накроется журнал? Молиться на btrfs (ака vapourware от orcale'а)?
для больших объемов есть FS с checksum'ами типа ZFS, HAMMER, NILFS, GPFS и тп. А вот JFS и XFS в пролете.
Журналирование можно сделать и в VM, т.е. заюзать GJournal, и не использовать fsck. Но полагаться на журнал - это, конечно, плевать на все, кроме ребутов/зависаний. Если начнет глючить контроллер или драйвер, то как тебя твой журнал спасет?
>Журналирование можно сделать и в VM, т.е. заюзать GJournal, и не использовать fsck.sorry,
Gjournaled file system has to be fscked, but only to handle orphaned
files. Such fsck on multiterabyte provider takes seconds, not hours.
>Если начнет глючить контроллер или драйвер, то как тебя
>твой журнал спасет?када глючит железо - надо его менять, а не выбирать ФС "понадежнее".
Винт может глюкнуть так, что больше не определится даже в биосе.
Так что, нужно на журналирование забивать из-за этого?
>када глючит железо - надо его менять, а не выбирать ФС "понадежнее".железо не вечно и backup никто не отменял, однако добавить к этому еще и надежную фс как ZFS не помешает
>Винт может глюкнуть так, что больше не определится даже в биосе.
>Так что, нужно на журналирование забивать из-за этого?это наоборот, повезло, т.к. ты узнаешь, что данные испорчены и может заюзать backup. А что ты будешь делать с silent error? Как от этого тя спасет журнал? checksum'ы помогут восстановить копиую из резерва или пометить файл как содержащий ошибку.
нет предела наворотам :)За сим и смотрю на ext4
>железо не вечно и backup никто не отменял, однако добавить к этому
>еще и надежную фс как ZFS не помешаетречь о комплексной политике обеспечения надежности. Полагаться на один журнал, на один raid-контроллер или на одни checksum'ы - портить себе нервы. К тому же в ZFS _есть_ журнал, помимо checksum'ов.
Бред. А ОЗУ заглючит или винт начнет вылетать, никакое ZFS не спасёт. Тогда смысл?!Кстати, GJOURNAL, по инфе с freebsd-stable@ - полная лажа, т.к. работает на уровне блочных устройств. Соответственно, оно даже не знает с чем в данный момент работает, с метаданными или с данными. Скорость соответствует... Короче, тупой и уродливый хак. Чисто чтобы можно было сказать - "оу, май ниггаз, у нас тоже есть журналируемая ФС".... Её, кстати, в качестве проекта summer of code наклепал наш соотечественник. Молодец, конечно, но, блин, сравнивать эту кривоту с вылизанной годами ext3..... клиника!
> А ОЗУ заглючит или винт начнет вылетать, никакое ZFS не спасёт. Тогда смысл?!В ZFS есть IO checksum, кроме block checksum, так что глюки памяти и винта таки в ней не страшны для данных...;)
> Молодец, конечно, но, блин, сравнивать эту кривоту с вылизанной годами ext3..... клиника!
Это та в которой месяцев 5-6 назад нашли такую ошибку, при которой терялись данные, просто на ровном месте, что аж сам Линус с горящим красным взором лично ошибку искал и исправлял, да, мега стабильность, вылизанная годами...*THUMBS UP*
>Это та в которой месяцев 5-6 назад нашли такую ошибку, при которой
>терялись данные, просто на ровном месте, что аж сам Линус с
>горящим красным взором лично ошибку искал и исправлял, да, мега стабильность,
>вылизанная годами...*THUMBS UP*что ты запоешь, когда в ZFS начнут находить проблемы??
съежжать на наличие ошибок так же тупо как утверждать что
в чем-то достаточно большом и сложном их нет
> что ты запоешь, когда в ZFS начнут находить проблемы??Думаю, что убью себя...:-D
> съежжать на наличие ошибок так же тупо как утверждать что
в чем-то достаточно большом и сложном их нет
Nick, дык разве я протестую, конечно они есть и в ZFS, просто тут один Одмин расказывал про мега стабильность, и безглючность ext3, как спасения всех, и всего, вот и вспомнилось, ну чтобы всё по чесно было, вот мы с Тобой поняли друг-друга, и не будем расказывать сказки, про то, что ext3 или ZFS, rock solid, а все остальные говно...;)
>Nick, дык разве я протестую, конечно они есть и в ZFS, просто
>тут один Одмин расказывал про мега стабильность, и безглючность ext3, как
>спасения всех, и всего, вот и вспомнилось, ну чтобы всё по
>чесно было, вот мы с Тобой поняли друг-друга, и не будем
>расказывать сказки, про то, что ext3 или ZFS, rock solid, а
>все остальные говно...;)ну вот :)
>> что ты запоешь, когда в ZFS начнут находить проблемы??
>Думаю, что убью себя...:-DНе делайте этого, пожалуйста :]
http://www.datacenterknowledge.com/archives/2008/Jan/16/joye...
(это в ZFS, но не на фре, а в предельно родном окружении -- opensolaris/sparc)
> Не делайте этого, пожалуйста :]http://www.datacenterknowledge.com/archives/2008/Jan/16/joye...
(это в ZFS, но не на фре, а в предельно родном окружении -- opensolaris/sparc)Michael Shigorin, баги есть везде и всегда, я во второй части поста с этим согласился, а так, спасибо за ссылку, прочёл, правда инфы очень мало, что конкретно случилось, не ясно толком, но в любом случае это лишь доказало в очередной раз, что везде есть ощибки...:)
>что ты запоешь, когда в ZFS начнут находить проблемы??_Nick_, вряд ли в ZFS найдут критические ошибки. Всё таки это основная продакшэн ф/с для самых различных по масштабу систем от Sun.
>_Nick_, вряд ли в ZFS найдут критические ошибки. Всё таки это основная
>продакшэн ф/с для самых различных по масштабу систем от Sun.вряд ли в ext3 будут проблемы, это же, все-таки, основная система
для всех Линух систем во всем мире.Но проблемы то нашлись... ;)
делай выводы и не говори ерунды.
> _Nick_, вряд ли в ZFS найдут критические ошибки. Всё таки это основная продакшэн ф/с для самых различных по масштабу систем от Sun.Что-то Вы Кирилл не туда совсем, нет я понимаю, я вот жертва SUN-овских маркетологов, но Вы то чего, ошибки есть везде, даже в ZFS, хоть так этого не хотелось бы, но всё же, Михаил Шигорин давал ссылку, я даже всё прочёл, хотя ситуация была не настолько страшная, так как там использовалась OpenSolaris Nevada build 49, согласитесь это несколько устаревшая _не продакшен_ версия, ну енто не суть важно, баг в ZFS таки там был ими найден, а значит она тоже не безгрешна, хотя такой баг проявился только в SUN Fire X4500 на громадном массиве, который имеет не каждый, но то что баг исправили это хорошо, а ещё лучьше то, что он проявился на OpenSolaris, а не на продакшен левел системе Solaris 10...:)
И как поможет IO checksum?! ОЗУ или винт начали мусор гнать, zfs увидело ошибку, возможно исправило (с битой-то памятью, ну ну). Дальше что? Куда это всё денется? Запишется на умирающий винт? И что получится?По-моему, такие фичи должны быть намного более интеллектуальными. Начал модуль ОЗУ ошибки выдавать, ОС его отключила (в linux, емнип, есть возможность на лету отключать участки памяти), начал винт умирать, ОС его из RAID САМА выдернула, живую инфу слила. В такой системе ZFS бы пригодился... А просто тупо checksum-ы считать - бесполезная ерунда...
> И как поможет IO checksum?! ОЗУ или винт начали мусор гнать, zfs увидело ошибку, возможно исправило (с битой-то памятью, ну ну). Дальше что? Куда это всё денется? Запишется на умирающий винт? И что получится?Запись не будет продолжаться, сюрприз??;)
> По-моему, такие фичи должны быть намного более интеллектуальными. Начал модуль ОЗУ ошибки выдавать, ОС его отключила (в linux, емнип, есть возможность на лету отключать участки памяти), начал винт умирать, ОС его из RAID САМА выдернула, живую инфу слила. В такой системе ZFS бы пригодился... А просто тупо checksum-ы считать - бесполезная ерунда...
Так вот в Solaris 10 так и происходит, есно на их серверах, ZFS тесно связана с FMA, что такое FMA в Solaris 10 сам найдёшь, и как оно всё взаимодействует, соотвественно падающий винт будет отключен от массива, а пулл будет переведён в состояние DEGRADED, а Администратор будет уведамлён о таком не приятном событии, есно, что можно будет продолжать работать с отставшейся частью пула, либо, если есть диски в hot spare режиме, то система заменит битый винт, винтом который отдан для hot spare, на автомате, посему ZFS и разработана для того, чтобы быть комплексным решением, по защите от повреждения данных и тесно взаимосвязана с остальной частью системы в Solaris 10...:)
>Бред. А ОЗУ заглючит или винт начнет вылетать, никакое ZFS не спасёт.
>Тогда смысл?!
>
>Кстати, GJOURNAL, по инфе с freebsd-stable@ - полная лажа, т.к. работает на
>уровне блочных устройств. Соответственно, оно даже не знает с чем в
>данный момент работает, с метаданными или с данными. Скорость соответствует... Короче,
>тупой и уродливый хак. Чисто чтобы можно было сказать - "оу,
>май ниггаз, у нас тоже есть журналируемая ФС".... Её, кстати, в
>качестве проекта summer of code наклепал наш соотечественник. Молодец, конечно, но,
>блин, сравнивать эту кривоту с вылизанной годами ext3..... клиника!Точно тролль. И дезинформатор, хоть бы почитать что потрудился. Gjournal использует хуки в коде FS, чтоб знать, когда сохраняются метаданные. Скорость по тестам у него иногда даже опережала SoftUpdates. И не тупой хак, а изящное решение, позволяющее добавить полное журналирование данных к любой FS c неслишком сильными изменениями. И я бы не стал называть поляка соотечественником. Да и что касается вылизанной годами ext3 - расскажите это сотрудникам датацентров, у которых она после нескольких месяцев работы при проверке fsck находила ошибки, несмотря на хваленый журнал (тут впору вспомнить о счетчике монтирований и дней без проверки - видимо, эти хаки вставлены не зря)...
Я больше доверяю инфе с freebsd-stable@, чем анонимным аналитикам с опеннета. В рассылке было сказано, возможно даже самим Voras-ом, что оно поэтому и может быть добавлено к любой FS, что НИЧЕГО ПРО ФС НЕ ЗНАЕТ, т.к. работает на уровне блочных устройств. Но об эффективности с таким подходом можно забыть!И что она быстрее UFS+SU только очень хитрых условиях! Сам разработчик написал что-то навроде "interesting feature". Сам подумай, если оно ВСЁ ЖУРНАЛИРУЕТ, как оно может быть быстрым?
>Я больше доверяю инфе с freebsd-stable@, чем анонимным аналитикам с опеннета. В
>рассылке было сказано, возможно даже самим Voras-ом, что оно поэтому и
>может быть добавлено к любой FS, что НИЧЕГО ПРО ФС НЕ
>ЗНАЕТ, т.к. работает на уровне блочных устройств. Но об эффективности с
>таким подходом можно забыть!
>
>И что она быстрее UFS+SU только очень хитрых условиях! Сам разработчик написал
>что-то навроде "interesting feature". Сам подумай, если оно ВСЁ ЖУРНАЛИРУЕТ, как
>оно может быть быстрым?Вот ты и есть анонимный аналитик, а я не только рассылки читаю, но и код пишу. Так что ты мне не свои досужие вымыслы давай, а ССЫЛКУ, где Voras именно такое и заявил.
>> када глючит железо - надо его менять, а не выбирать ФС "понадежнее".Знать бы когда оно решит глючить. ZFS в этом плане очень удобное решение.
>Если начнет глючить контроллер или драйвер, то как тебя твой журнал спасет?Так, для справки: замечено, что при битой (разогнанной, перегретой...) памяти у людей xfs отваливало систему в ro с внятной руганью в лог.
Про развал журнала пока только слышал, но "не фонтан". Самому сталкиваться не доводилось.
Кажется, там рейд с батарейкой суппорт радостно дёргал по питанию (то ли на агаве, то ли на мастерхосте).
>>> при количестве inode-ов в 40млн
>>а зачем тебе столько inode'ов? язык чесать?
>
>А вы давно на емкость современных HDD смотрели?Далеко не любой файл весит
>по 600 мегабайт, а?Ну в общем стандартные ответы из рубрики "свое
>... не пахнет" :\А причем тут емкость HDD, а? покажите мне df -i хоть с одной промышленной системы, где есть разделы с более чем миллионом файлов.
>покажите мне df -i хоть с одной промышленной системы,
>где есть разделы с более чем миллионом файлов.До кластера отсюда не дотянуться :), а из того, что поближе --
/dev/mdN xfs 890M 986K 889M 1% ~ftp
/dev/mdK xfs 110M 324K 109M 1% ~ftp/pub/Linux/ALT
>>покажите мне df -i хоть с одной промышленной системы,
>>где есть разделы с более чем миллионом файлов.
>
>До кластера отсюда не дотянуться :), а из того, что поближе --
>
>
>/dev/mdN xfs 890M 986K 889M 1% ~ftp
>/dev/mdK xfs 110M 324K 109M 1% ~ftp/pub/Linux/ALTНу и? Оба раздела не превышают даже ОДНОГО миллиона. Тогда как в исходном посте говорилось про 40.
> А причем тут емкость HDD, а? покажите мне df -i хоть с одной
> промышленной системы, где есть разделы с более чем миллионом файлов.[root@lxwdc1 ~]# df -ih
Filesystem Inodes IUsed IFree IUse% Mounted on
[...]
/dev/mapper/VolGroup01-LogVol00
2.5G 129M 2.4G 6% /mnt/aoe1
>[оверквотинг удален]
>
> [root@lxwdc1 ~]# df -ih
> Filesystem
> Inodes IUsed IFree IUse% Mounted on
>
> [...]
> /dev/mapper/VolGroup01-LogVol00
>
>
> 2.5G 129M 2.4G 6% /mnt/aoe1Хм. А что у вас там лежит, на такое количество файлов? И какая вложенность каталогов?
>> 2.5G 129M 2.4G 6% /mnt/aoe1
>Хм. А что у вас там лежит, на такое количество файлов? И какая вложенность каталогов?Это e-discovery NAS.
http://en.wikipedia.org/wiki/Data_processing_architecture_fo...
>>> 2.5G 129M 2.4G 6% /mnt/aoe1
>>Хм. А что у вас там лежит, на такое количество файлов? И какая вложенность каталогов?
>
>Это e-discovery NAS.
>
>http://en.wikipedia.org/wiki/Data_processing_architecture_fo...А, ну так NAS/SAN нередко имеют собственную FS, железка может даже не иметь на себе опенсорсную ось.
> Вчера вычитал в рассылке freebsd-stable@Дайте, пожалуйста, ссылку...
> Для проверки террабайтной UFS2 fsck надо гиг ОЗУ, причём в kernelspace, соответственно,
> надо /boot/loader.conf править и перегружаться.Это странно, fsck работает в userspace и использует своп если ей надо. fsck *может* потребоватся гиг виртуальной памяти на терабайт диска, но это не обязательно, зависит от параметров файловой системы. См. http://groups.google.com/group/lucky.freebsd.fs/browse_threa...
Для сравнения, полная проверка 15T xfs c дефолтными настройками на CentOS 4.5 у меня заняла 26 часов и 18 гиг памяти. XFS, кстати, не поддерживает бэкграунд чекинг.
>> Вчера вычитал в рассылке freebsd-stable@
>Дайте, пожалуйста, ссылку...Вероятне всего, имеется ввиду следующий тред:
http://groups.google.com/group/lucky.freebsd.stable/browse_t...Кстати, "матерый бздун Oliver Fromme" там и повторил, что при дефолтных newfs-ных параметрах для fsck на 1ТБ UFS2 надо 1G памяти, только в userspace. Естественно, совет добавить памяти им был дан для ускорения fsck, дабы последний не лез в swap. Я могу предположить, что проблема озвученная в треде была вызвана банальным неподмонтированым swap-ом в single user mode.
Не про какую необходимость правки /boot/loader.conf и перезагрузку там и не упоминалось. Только топикстартер зачем-то прописал бесполезные параметры kern.maxdsiz и kern.dfldsiz, которые обычно осью определяются правильно. Но это его собственные тараканы. Могу напомнить что кол-во памяти для ядерного malloc, т.е. фактически kernelspace выставляется через vm.kmem_size и vm.kmem_size_max, но на fsck не особо влияют.Как резюме, можно посоветовать гражданину Одмину учить английский вместо олбанского, может тогда хоть смысл текста начнет понимать.
Не, а кто чуваку виноват, что он отформатировал такой большой раздел с дефолтными параметрами. У людей вон есть UFS2 на 6 терабайт нормально отформатированная есть, и ничего, fsck работает. Что предложили вытащить - а что еще советовать чуваку, если он уже в ситуацию попал? Убиться об стену? Неконструктивно.>ZFS ещё совсем сырое и по дизайну мегатормозное. GJOURNAL ещё сырое.
Ага, все умрем. Не все так печально. ZFS считается экспериментальной, и кстати довольно быстрой. И для экспериментальной FS у нее весьма высокая надежность. Плюс - класс задач - терабайты не везде нужны пока. У меня вот 300-гиговый раздел на UFS2+SU проверяется за считанные секунды.
О том что аллокатор памяти в libc фиговат для потоковых приложений известно давно.
>О том что аллокатор памяти в libc фиговат для потоковых приложений известно давно.Да он и вообще до недавних пор (e.g. в glibc-2.5) был не сильно-то адекватен текущему положению дел в linux-2.6 :(
>FreeBSD 7.0 does not support the MFS file system; the nearest alternative is the tmpfs filesystem which was used for this test.Понравилось сравнение тёплого с мягким, ближе просто некуда. Добавил бы тогда NetBSD с tmpfs для интереса.
>>FreeBSD 7.0 does not support the MFS file system; the nearest alternative is the tmpfs filesystem which was used for this test.
>
>Понравилось сравнение тёплого с мягким, ближе просто некуда. Добавил бы тогда NetBSD
>с tmpfs для интереса.Согласен. И вообще, это когда MFS исключили из 7-ки? tmpfs же все еще экспериментальная (как и zfs)...
SLAB ili SLUB bil v fedore ?
>SLAB ili SLUB bil v fedore ?SLUB
Диллон только обещает. Весь kerneltrap.org исписал, писатель... Посмотрим что он там со своим Hammer сделает.
нечесный тест.
Берет Бздю в карренте - брал бы и 2.6.25-rc4/5 ядро.А так - очередной бойан
Это на Опеннет ее очередная опечатка:"The following graph compares FreeBSD 7.0 and Linux 2.6.24+glibc 2.7"
>Это на Опеннет ее очередная опечатка:А это уже моя опечатка:))). Конечно, "на Опеннете очередная" :)
да ты хоть по ссылке сходи.
Первый де график - FBSD-8.0 и Fedora с 2.6.24бойан
>да ты хоть по ссылке сходи.
>Первый де график - FBSD-8.0 и Fedora с 2.6.24
>
>бойанЫыы, просто само тестирование меня самой своей идеей не впечатлило, изучать не стал. :( Впрочем, если я не ошибаюсь, там действительно аллокаторы одинаковые...
>Это на Опеннет ее очередная опечатка:
>
>"The following graph compares FreeBSD 7.0 and Linux 2.6.24+glibc 2.7"Не опечатка, тестировали именно FreeBSD 8, читайте дальше пояснение к графикам:
"This graph shows FreeBSD 8.0 but FreeBSD 7.0 does not perform substantially differently"
Нравится тенденция тестирования DragonflyBSD вместе с другими системами. По всем тестам она сливает просто катастрофично. Надеюсь, Диллон одумается и закроет проект, а полезные наработки типа hammer и vkernel перенесет на FreeBSD CURRENT. Ибо DF чуть менее, чем полностью бесполезная трата времени разработчивов. PS. Еще умиляют местные защитники DFBSD, которые сами ее не используют :)
>Нравится тенденция тестирования DragonflyBSD вместе с другими системами. По всем тестам она
>сливает просто катастрофично. Надеюсь, Диллон одумается и закроет проект, а полезные
>наработки типа hammer и vkernel перенесет на FreeBSD CURRENT. Ибо DF
>чуть менее, чем полностью бесполезная трата времени разработчивов. PS. Еще умиляют
>местные защитники DFBSD, которые сами ее не используют :)Блин, ну вам-то лично чем эта ОС мешает?! Я её тоже не использовал напрямую, но при этом я пользуюсь мелкими и не очень наработками, которые приходят именно из этой ОС. И то, что они приходят именно из DragonFly BSD говорит о том, что именно организация разработки этой ОС лучше всего подходит для появления данных конструкций (драйверов, например).
И не надо говорить, что разработчики DragonFly BSD лучше бы пригодились в других проектах. Во-первых, если бы им лучше работалось в других проектах, то они работали бы в других проектах, а там, где им лучше работается, там и результаты лучше (поскольку ОС открытая, то польза, опять же, всем - см. выше). А во-вторых, вы предпочитаете конкуренцию или моно-/олигополию?
Если честно, я снимаю шляпу перед разработчиками DFBSD, что они взялись за этот проект, когда рынок, казалось, уже давно был поделен.
Ну а насчёт того, что 4.x устарело - надоело, чесслово. Если для вас важнее то, что появилось только в 5.x/6.x/7.x - то пользуйтесь, пожалуйста, никто вам не мешает! Но, пардон, обсирать-то других зачем?! Глупо выглядит, а вовсе не понтово.
кста, кто-нить нашел его комментарии по тестам жабы:
http://people.freebsd.org/~kris/scaling/specjava.png
http://people.freebsd.org/~kris/scaling/specjbb2005.pngа? или это недоделанный бенчмарк?
После тестов SMP нет доверия к этому товарищу.
>После тестов SMP нет доверия к этому товарищу.Nick Piggin гонял недавно на ванильном 2.6.25-rc4, а Kriss тогда еще гонял на 2.6.23. При чем тут доверие, просто те тесты MySQL устарели...
А вообще прикольно наблюдать за этими товарищами. Ждем ответ от Nick Piggin =)
Да я это именно из-за 2.6.22. Результаты тут http://www.kernel.org/pub/linux/kernel/people/npiggin/sysbench/ очень отличаются от результатов Криса.
> А вообще прикольно наблюдать за этими товарищами. Ждем ответ от Nick Piggin =)А бенчмарки без политики не бывают. ;)
да уж линух
помниться знакомым занимающимся железом притянули винт который толи начал сыпаться толи еще что то
но линухоид с ним ничего сделать несмог
я при этом присутсвовал(когда принесли и обясняли проблему)
хардовики протестили и сказали проблемы с винтом нет
эт где то на уровне операционки
ну линуха под рукой небыло
запустил bsd 4
прочекал ее bsd шным fsck
она там все пофиксила
винт вернули линухоиду......
он аж плакал - поскольку там был биллинг и вся статистика за несколько лет по клиентам
вот
а вы кричите линух линух....
кто ж знал, что ты такой идиот и будешь использовать fsck_ufs или fsck_ffs вместо fsck.ext2 или fsck.ext3 (из комплекта sysutils/e2fsprogs)ССЗБ!
если бы небыл идиотом то понял бы что так и было
или мне каждому идиоту разжопывать и в рот пихать?
{kind=link}
{kind=link}