| Каталог документации / Раздел "Программирование, языки" | (Архив | Для печати) |
| ||
Учебное пособие + примеры
[ Автор: Илья Евсеев ]
[ Организация: ИВВиБД ]
[ Подразделение: ЦСТ ]
[ Оригинал документа на ilya-evseev.narod.ru ]
MPI - это стандарт на программный инструментарий для обеспечения связи между ветвями параллельного приложения.
MPI расшифровывается как "Message passing interface" ("Взаимодействие через передачу сообщений"). Несколько путает дело тот факт, что этот термин уже применяется по отношению к аппаратной архитектуре ЭВМ. Программный инструментарий MPI реализован в том числе и для ЭВМ с такой архитектурой.
MPI предоставляет программисту единый механизм взаимодействия
ветвей внутри параллельного приложения независимо от машинной
архитектуры (однопроцессорные / многопроцессорные с общей/раздельной
памятью), взаимного расположения ветвей (на одном процессоре /
на разных) и API операционной системы.
( API = "applications programmers interface"
= "интерфейс разработчика приложений" )
Программа, использующая MPI, легче отлаживается (сужается простор для совершения стереотипных ошибок параллельного программирования) и быстрее переносится на другие платформы (в идеале, простой перекомпиляцией).
В настоящее время разными коллективами разработчиков написано несколько программных пакетов, удовлетворяющих спецификации MPI, в частности: MPICH, LAM, HPVM и так далее. Они выступают базовыми при переносе MPI на новые архитектуры ЭВМ. Здесь в пособии рассматриваются разновидности MPICH. Это сделано по двум причинам:
Минимально в состав MPI входят: библиотека программирования (заголовочные и библиотечные файлы для языков Си, Си++ и Фортран) и загрузчик приложений.
Дополнительно включаются: профилирующий вариант библиотеки (используется на стадии тестирования параллельного приложения для определения оптимальности распараллеливания); загрузчик с графическим и сетевым интерфейсом для X-Windows и проч.
Структура каталогов MPICH выполнена в полном соответствии с традициями Юникса: bin, include, lib, man, src, ... Минимальный набор функций прост в освоении и позволяет быстро написать надежно работающую программу. Использование же всей мощи MPI позволит получить БЫСТРО работающую программу - при сохранении надежности.
Первоначально весь текст данного пособия был собран в одном документе. Теперь он разбит на три части:
Параллельное приложение состоит из нескольких ветвей, или процессов, или задач, выполняющихся одновременно. Разные процессы могут выполняться как на разных процессорах, так и на одном и том же - для программы это роли не играет, поскольку в обоих случаях механизм обмена данными одинаков. Процессы обмениваются друг с другом данными в виде сообщений. Сообщения проходят под идентификаторами, которые позволяют программе и библиотеке связи отличать их друг от друга. Для совместного проведения тех или иных расчетов процессы внутри приложения объединяются в группы. Каждый процесс может узнать у библиотеки связи свой номер внутри группы, и, в зависимости от номера приступает к выполнению соответствующей части расчетов.
Термин "процесс" используется также в Юниксе, и здесь нет путаницы: в MPI ветвь запускается и работает как обычный процесс Юникса, связанный через MPI с остальными процессами, входящими в приложение. В остальном процессы следует считать изолированными друг от друга: у них разные области кода, стека и данных (короче, смотрите описание Юниксовских процессов). Говорят, что процессы имеют раздельную память (separate memory).
Особенность MPI: понятие области связи (communication domains). При запуске приложения все процессы помещаются в создаваемую для приложения общую область связи. При необходимости они могут создавать новые области связи на базе существующих. Все области связи имеют независимую друг от друга нумерацию процессов. Программе пользователя в распоряжение предоставляется коммуникатор - описатель области связи. Многие функции MPI имеют среди входных аргументов коммуникатор, который ограничивает сферу их действия той областью связи, к которой он прикреплен. Для одной области связи может существовать несколько коммуникаторов таким образом, что приложение будет работать с ней как с несколькими разными областями. В исходных текстах примеров для MPI часто используется идентификатор MPI_COMM_WORLD. Это название коммуникатора, создаваемого библиотекой автоматически. Он описывает стартовую область связи, объединяющую все процессы приложения.
В manual pages особо подчеркивается принадлежность описываемой функции к той или иной категории. При первом чтении этот раздел можно пропустить, возвращаясь к нему по мере ознакомления с документацией. Вкратце:
Блокирующие - останавливают (блокируют) выполнение процесса до тех пор, пока производимая ими операция не будет выполнена. Неблокирующие функции возвращают управление немедленно, а выполнение операции продолжается в фоновом режиме; за завершением операции надо проследить особо. Неблокирующие функции возвращают квитанции ("requests"), которые погашаются при завершении. До погашения квитанции с переменными и массивами, которые были аргументами неблокирующей функции, НИЧЕГО ДЕЛАТЬ НЕЛЬЗЯ.
Локальные - не инициируют пересылок данных между ветвями. Большинство информационных функций является локальными, т.к. копии системных данных уже хранятся в каждой ветви. Функция передачи MPI_Send и функция синхронизации MPI_Barrier НЕ являются локальными, поскольку производят пересылку. Следует заметить, что, к примеру, функция приема MPI_Recv (парная для MPI_Send) является локальной: она всего лишь пассивно ждет поступления данных, ничего не пытаясь сообщить другим ветвям.
Коллективные - должны быть вызваны ВСЕМИ ветвями-абонентами того коммуникатора, который передается им в качестве аргумента. Несоблюдение для них этого правила приводит к ошибкам на стадии выполнения программы (как правило, к повисанию).
Регистр букв : важен в Си, не играет роли в Фортране.
Все идентификаторы начинаются с префикса "MPI_". Это правило без исключений. Не рекомендуется заводить пользовательские идентификаторы, начинающиеся с этой приставки, а также с приставок "MPID_", "MPIR_" и "PMPI_", которые используются в служебных целях.
Если идентификатор сконструирован из нескольких слов, слова в нем разделяются подчерками: MPI_Get_count, MPI_Comm_rank. Иногда, однако, разделитель не используется: MPI_Sendrecv, MPI_Alltoall.
Порядок слов в составном идентификаторе выбирается по принципу "от общего к частному": сначала префикс "MPI_", потом название категории ( Type, Comm, Group, Attr, Errhandler и т.д.), потом название операции ( MPI_Errhandler_create, MPI_Errhandler_set, ...). Наиболее часто употребляемые функции выпадают из этой схемы: они имеют "анти-методические", но короткие и стереотипные названия, например MPI_Barrier, или MPI_Unpack.
Имена констант (и неизменяемых пользователем переменных) записываются полностью заглавными буквами: MPI_COMM_WORLD, MPI_FLOAT. В именах функций первая за префиксом буква - заглавная, остальные маленькие: MPI_Send, MPI_Comm_size.
Такая нотация по первому времени может показаться непривычной, однако ее использование быстро входит в навык. Надо признать, что она делает исходные тексты более читабельными.
Здесь в сжатом виде изложены основные отличия особенности реализации MPI для Фортрана. С их учетом программисты, пишущие на языке Фортран, смогут приступить к изучению дальнейшего материала.
include 'mpif.h'Этот файл содержит описания переменных и констант.
Си: errcode = MPI_Comm_rank( MPI_COMM_WORLD, &rank );
Фортран: CALL MPI_COMM_RANK ( MPI_COMM_WORLD, rank, ierror )
Там, где MPI требуется знать местонахождение в памяти таких данных, которые по ссылке не передашь (например, при конструировании пользовательских типов), используется подпрограмма MPI_ADDRESS.
MPI_Status status; /* переменная типа структура */
MPI_Probe( MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status );
/* теперь проверяем поля заполненной структуры */
if( status.MPI_SOURCE == 1 ) { ... }
if( status.MPI_TAG == tagMsg1 ) { ... }
INTEGER status(MPI_STATUS_SIZE) CALL MPI_PROBE( MPI_ANY_SOURCE,MPI_ANY_TAG,MPI_COMM_WORLD, status ) IF( status(MPI_SOURCE) .EQ. 1 ) .... IF( status(MPI_TAG) .EQ. tagMsg1 ) ...ну и так далее...
Вот пример на Фортране, взятый из MPI-UX. Надеюсь, Convex простит мне этот маленький плагиат.
Существует несколько функций, которые используются в любом, даже самом коротком приложении MPI. Занимаются они не столько собственно передачей данных, сколько ее обеспечением:
MPI_Init( &argc, &argv );Она получает адреса аргументов, стандартно получаемых самой main от операционной системы и хранящих параметры командной строки. В конец командной строки программы MPI-загрузчик mpirun добавляет ряд информационных параметров, которые требуются MPI_Init. Это показывается в примере 0.
MPI_Abort( описатель области связи, код ошибки MPI );Вызов MPI_Abort из любой задачи принудительно завершает работу ВСЕХ задач, подсоединенных к заданной области связи. Если указан описатель MPI_COMM_WORLD, будет завершено все приложение (все его задачи) целиком, что, по-видимому, и является наиболее правильным решением. Используйте код ошибки MPI_ERR_OTHER, если не знаете, как охарактеризовать ошибку в классификации MPI.
MPI_Finalize();Настоятельно рекомендуется не забывать вписывать эту инструкцию перед возвращением из программы, то есть:
int size, rank;
MPI_Comm_size( MPI_COMM_WORLD, &size );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
Использование MPI_Init, MPI_Finalize, MPI_Comm_size и MPI_Comm_rank демонстрирует пример 0. Использование MPI_Abort будет показано далее, в примере 1.
Это самый простой тип связи между задачами: одна ветвь вызывает функцию передачи данных, а другая - функцию приема. В MPI это выглядит, например, так:
int buf[10];
MPI_Send( buf, 5, MPI_INT, 1, 0, MPI_COMM_WORLD );
int buf[10];
MPI_Status status;
MPI_Recv( buf, 10, MPI_INT, 0, 0, MPI_COMM_WORLD, &status );
Аргументы функций:
С одной стороны, мы передаем в MPI_Recv номер задачи, от которой ждем сообщение, и его идентификатор; а с другой - получаем их от MPI в структуре status? Это сделано потому, что MPI_Recv может быть вызвана с аргументами-джокерами ("принимай что угодно/от кого угодно"), и после такого приема данных программа узнает фактические номер/идентификатор, читая поля MPI_SOURCE и MPI_TAG из структуры status.
Поле MPI_ERROR, как правило, проверять необязательно - обработчик ошибок, устанавливаемый MPI по умолчанию, в случае сбоя завершит выполнение программы ДО возврата из MPI_Recv. Таким образом, после возврата из MPI_Recv поле status.MPI_ERROR может быть равно только 0 (или, если угодно, MPI_SUCCESS);
Тип MPI_Status не содержит поля, в которое записывалась бы фактическая длина пришедшего сообщения. Длину можно узнать так:
MPI_Status status;
int count;
MPI_Recv( ... , MPI_INT, ... , &status );
MPI_Get_count( &status, MPI_INT, &count );
/* ... теперь count содержит количество принятых ячеек */
Обратите внимание, что аргумент-описатель типа у MPI_Recv
и MPI_Get_count должен быть одинаковым, иначе, в зависимости
от реализации:
Итак, по возвращении из MPI_Recv поля структуры status содержат информацию о принятом сообщении, а функция MPI_Get_count возвращает количество фактически принятых данных. Однако имеется еще одна функция, которая позволяет узнать о характеристиках сообщения ДО того, как сообщение будет помещено в приемный пользовательский буфер: MPI_Probe. За исключением адреса и размера пользовательского буфера, она имеет такие же параметры, как и MPI_Recv. Она возвращает заполненную структуру MPI_Status и после нее можно вызвать MPI_Get_count. Стандарт MPI гарантирует, что следующий за MPI_Probe вызов MPI_Recv с теми же параметрами (имеются в виду номер задачи-передатчика, идентификатор сообщения и коммуникатор) поместит в буфер пользователя именно то сообщение, которое было принято функцией MPI_Probe. MPI_Probe нужна в двух случаях:
MPI_Probe( MPI_ANY_SOURCE, tagMessageInt, MPI_COMM_WORLD, &status ); /* MPI_Probe вернет управление после того как примет */ /* данные в системный буфер */ MPI_Get_count( &status, MPI_INT, &bufElems ); buf = malloc( sizeof(int) * bufElems ); MPI_Recv( buf, bufElems, MPI_INT, ... /* ... дальше параметры у MPI_Recv такие же, как в MPI_Probe ); */ /* MPI_Recv останется просто скопировать */ /* данные из системного буфера в пользовательский */Вместо этого, конечно, можно просто завести на приемной стороне буфер заведомо большой, чтобы вместить в себя самое длинное из возможных сообщений, но такой стиль не является оптимальным, если длина сообщений "гуляет" в слишком широких пределах.
MPI_Recv( floatBuf, floatBufSize, MPI_FLOAT, MPI_ANY_SOURCE, tagFloatData, ... ); MPI_Recv( intBuf, intBufSize, MPI_INT, MPI_ANY_SOURCE, tagIntData, ... ); MPI_Recv( charBuf, charBufSize, MPI_CHAR, MPI_ANY_SOURCE, tagCharData, ... );Теперь, если в момент выполнения сообщение с идентификатором tagCharData придет раньше двух остальных, MPI будет вынужден "законсервировать" его на время выполнения первых двух вызовов MPI_Recv. Это чревато непроизводительными расходами памяти. MPI_Probe позволит задать порядок извлечения сообщений в буфер пользователя равным порядку их поступления на принимающую сторону, делая это не в момент компиляции, а непосредственно в момент выполнения:
for( i=0; i<3; i++ ) {
MPI_Probe( MPI_ANY_SOURCE,MPI_ANY_TAG,MPI_COMM_WORLD,&status );
switch( status.MPI_TAG ) {
case tagFloatData:
MPI_Recv( floatBuf, floatBufSize, MPI_FLOAT, ... );
break;
case tagIntData:
MPI_Recv( intBuf, intBufSize, MPI_INT, ... );
break;
case tagCharData:
MPI_Recv( charBuf, charBufSize, MPI_CHAR, ... );
break;
} /* конец switch */
} /* конец for */
Многоточия здесь означают, что последние 4 параметра
у MPI_Recv такие же, как и у предшествующей им MPI_Probe.
Использование MPI_Probe продемонстрировано
в примере 2.
В примере 2 используются два джокера: MPI_ANY_SOURCE для номера задачи-отправителя ("принимай от кого угодно") и MPI_ANY_TAG для идентификатора получаемого сообщения ("принимай что угодно"). MPI резервирует для них какие-то отрицательные целые числа, в то время как реальные идентификаторы задач и сообщений лежат всегда в диапазоне от 0 до 32767. Пользоваться джокерами следует с осторожностью, потому что по ошибке таким вызовом MPI_Recv может быть захвачено сообщение, которое должно приниматься в другой части задачи-получателя.
Если логика программы достаточно сложна, использовать джокеры можно ТОЛЬКО в функциях MPI_Probe и MPI_Iprobe, чтобы перед фактическим приемом узнать тип и количество данных в поступившем сообщении (вообще-то, можно принимать, и не зная количества - был бы приемный буфер достаточно вместительным, но тип для MPI_Recv надо указывать явно - а он может быть разным в сообщениях с разными идентификаторами).
Достоинство джокеров: приходящие сообщения извлекаются по мере поступления, а не по мере вызова MPI_Recv с нужными идентификаторами задач/сообщений. Это экономит память и увеличивает скорость работы.
MPI_Comm_size( MPI_COMM_WORLD, &size );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
if( rank % 2 ) {
/* Ветви с четными номерами сначала
* передают следующим нечетным ветвям,
* потом принимают от предыдущих
*/
MPI_Send(..., ( rank+1 ) % size ,...);
MPI_Recv(..., ( rank+size-1 ) % size ,...);
} else {
/* Нечетные ветви поступают наоборот:
* сначала принимают от предыдущих ветвей,
* потом передают следующим.
*/
MPI_Recv(..., ( rank-1 ) % size ,...);
MPI_Send(..., ( rank+1 ) % size ,...);
}
MPI_Send(..., anyRank ,...); /* Посылаем данные */
MPI_Recv(..., anyRank ,...); /* Принимаем подтверждение */
Ситуация настолько распространенная, что в MPI специально введены две функции, осуществляющие одновременно посылку одних данных и прием других. Первая из них - MPI_Sendrecv. Ее прототип содержит 12 параметров: первые 5 параметров такие же, как у MPI_Send, остальные 7 параметров такие же как у MPI_Recv. Один ее вызов проделывает те же действия, для которых в первом фрагменте требуется блок IF-ELSE с четырьмя вызовами. Следует учесть, что:
MPI_Sendrecv_replace помимо общего коммуникатора использует еще и общий для приема-передачи буфер. Не очень удобно, что параметр count получает двойное толкование: это и количество отправляемых данных, и предельная емкость входного буфера. Показания к применению:
MPI_Sendrecv_replace так же гарантированно не вызывает клинча.
Что такое клинч? Дальше следует краткая иллюстрация этой ошибки, очень распространенной там, где для пересылок используется разделяемая память.
Вариант 1:
-- Ветвь 1 -- -- Ветвь 2 --
Recv( из ветви 2 ) Recv( из ветви 1 )
Send( в ветвь 2 ) Send( в ветвь 1 )
Вариант 1 вызовет клинч, какой бы инструментарий не использовался: функция приема не вернет управления до тех пор, пока не получит данные; поэтому функция передачи не может приступить к отправке данных; поэтому функция приема... и так до самого SIG_KILL;)
Вариант 2:
-- Ветвь 1 -- -- Ветвь 2 --
Send( в ветвь 2 ) Send( в ветвь 1 )
Recv( из ветви 2 ) Recv( из ветви 1 )
Вариант 2 вызовет клинч, если функция передачи возвращает управление только после того, как данные попали в пользовательский буфер на приемной стороне. Скорее всего, именно так и возьмется реализовывать передачу через разделяемую память/семафоры программист-проблемщик.
Однако при использовании MPI зависания во втором варианте не произойдет! MPI_Send, если на приемной стороне нет готовности (не вызван MPI_Recv), не станет ее дожидаться, а положит данные во временный буфер и вернет управление программе НЕМЕДЛЕННО. Когда MPI_Recv будет вызван, данные он получит не из пользовательского буфера напрямую, а из промежуточного системного. Буферизация - дело громоздкое - может быть, и не всегда сильно экономит время (особенно на SMP-машинах), зато повышает надежность: делает программу более устойчивой к ошибкам программиста.
MPI_Sendrecv и MPI_Sendrecv_replace также делают программу более устойчивой: с их использованием программист лишается возможности перепутать варианты 1 и 2.
Действительно, зачем? Стандартные функции пересылки данных, например, memcpy, прекрасно обходятся без подобной информации - им требуется знать только размер в байтах. Вместо одного такого аргумента функции MPI получают два: количество элементов некоторого типа и символический описатель указанного типа (MPI_INT, и т.д.). Причин тому несколько:
typedef struct {
char c;
double d;
} CharDouble;
Создание собственных типов описывается дальше по тексту.
Все вышеперечисленные функции приема-передачи оперируют массивами - непрерывными последовательностями однотипных данных. Однако программисту может потребоваться пересылать данные, которые либо разнотипны, либо не-непрерывно расположены в памяти, либо то и другое сразу (особо тяжелый случай).
Вариант 1 (настолько тупой и медленный, что никогда не применяется). Каждый элемент в разнотипном наборе данных посылается отдельно:
#define msgTag 10
struct {
int i;
float f[4];
char c[8];
} s;
MPI_Send(&s.i, 1, MPI_INT, targetRank, msgTag, MPI_COMM_WORLD );
MPI_Send( s.f, 4, MPI_FLOAT, targetRank, msgTag+1, MPI_COMM_WORLD );
MPI_Send( s.c, 8, MPI_CHAR, targetRank, msgTag+2, MPI_COMM_WORLD );
... и на приемной стороне столько же раз вызывается MPI_Recv.
Вариант 2 ("классический"). Функция приема/передачи вызывается один раз, но до/после нее многократно вызывается функция упаковки/распаковки:
Передача
========
int bufPos = 0;
char tempBuf[ sizeof(s) ];
MPI_Pack(&s.i, 1, MPI_INT, tempBuf, sizeof(tempBuf), &bufPos, MPI_COMM_WORLD );
MPI_Pack( s.f, 4, MPI_FLOAT, tempBuf, sizeof(tempBuf), &bufPos, MPI_COMM_WORLD );
MPI_Pack( s.c, 8, MPI_CHAR, tempBuf, sizeof(tempBuf), &bufPos, MPI_COMM_WORLD );
MPI_Send( tempBuf, bufPos, MPI_BYTE, targetRank, msgTag, MPI_COMM_WORLD );
Прием
=====
int bufPos = 0;
char tempBuf[ sizeof(s) ];
MPI_Recv( tempBuf, sizeof(tempBuf), MPI_BYTE, sourceRank, msgTag,
MPI_COMM_WORLD, &status );
MPI_Unpack( tempBuf, sizeof(tempBuf), &bufPos,&s.i, 1, MPI_INT, MPI_COMM_WORLD);
MPI_Unpack( tempBuf, sizeof(tempBuf), &bufPos, s.f, 4, MPI_FLOAT,MPI_COMM_WORLD);
MPI_Unpack( tempBuf, sizeof(tempBuf), &bufPos, s.c, 8, MPI_CHAR, MPI_COMM_WORLD);
Вариант 2 обозван здесь классическим, потому что пришел в MPI из PVM, где предлагается в качестве единственного. Он прост в понимании, за что его все и любят. Замечания по применению:
int bufSize = 0;
void *tempBuf;
MPI_Pack_size( 1, MPI_INT, MPI_COMM_WORLD, &bufSize );
MPI_Pack_size( 4, MPI_FLOAT, MPI_COMM_WORLD, &bufSize );
MPI_Pack_size( 8, MPI_CHAR, MPI_COMM_WORLD, &bufSize );
tempBuf = malloc( bufSize );
/* ... теперь можем упаковывать, не опасаясь переполнения */
Вариант 3 ("жульнический"). Если есть уверенность, что одни и те же типы данных в обеих ветвях приложения имеют одинаковое двоичное представление, то:
Передача: MPI_Send( &s, sizeof(s), MPI_BYTE, ... );
Прием: MPI_Recv( &s, sizeof(s), MPI_BYTE, ... );
А все, чем чреват такой подход, подробно перечислено в предыдущей главе.
Общие правила:
При первом прочтении можете пропустить описание конструкторов MPI_Type_vector и MPI_Type_indexed, сразу перейдя к MPI_Type_struct.
MPI_Type_contiguous : самый простой конструктор типа, он создает описание массива. В следующем примере оба вызова MPI_Send делают одно и то же.
int a[16];
MPI_Datatype intArray16;
MPI_Type_contiguous( 16, MPI_INT, &intArray16 );
MPI_Type_commit( &intArray16 );
MPI_Send( a, 16, MPI_INT, ... );
MPI_Send( a, 1, intArray16, ... );
MPI_Type_free( &intArray16 );
Функция MPI_Type_count вернет количество ячеек в переменной
составного типа: после MPI_Type_count( intArray16, &count ) значение
count станет равным 16. Как правило, прямой необходимости использовать
эти функции нет, и тем не менее.
MPI_Type_vector : служит для описания множества однотипных равноудаленных в памяти массивов данных. Позволяет весьма изощренные манипуляции с данными. Он создает описание для не-непрерывной последовательности элементов, которые, в свою очередь, составлены из непрерывной последовательности ячеек базового (уже определенного) типа:
MPI_Type_vector( int count, /* количество элементов в новом типе */ int blocklength, /* количество ячеек базового типа в одном элементе */ int stride, /* расстояние между НАЧАЛАМИ эл-тов, в числе ячеек */ MPI_Datatype oldtype, /* описатель базового типа, т.е. типа ячейки */ MPI_Datatype &newtype /* cсылка на новый описатель */ );То есть:
MPI_Type_indexed : расширение "векторного" описателя; длины массивов и расстояния между ними теперь не фиксированы, а у каждого массива свои. Соответственно, аргументы #2 и #3 здесь - не переменные, а массивы: массив длин и массив позиций.
Пример: создание шаблона для выделения верхней правой части матрицы.
#define SIZE 100
float a[ SIZE ][ SIZE ];
int pos[ SIZE ]
int len[ SIZE ];
MPI_Datatype upper;
...
for( i=0; i<SIZE; i++ ) { /* xxxxxx */
pos[i] = SIZE*i + i; /* .xxxxx */
len[i] = SIZE - i; /* ..xxxx */
} /* ...xxx */
MPI_Type_indexed(
SIZE, /* количество массивов в переменной нового типа */
len, /* длины этих массивов */
pos, /* их позиции от начала переменной, */
/* отсчитываемые в количестве ячеек */
MPI_FLOAT, /* тип ячейки массива */
&upper );
MPI_Type_commit( &upper );
/* Поступающий поток чисел типа 'float' будет
* размещен в верхней правой части матрицы 'a'
*/
MPI_Recv( a, 1, upper, .... );
Аналогично работает функция MPI_Type_hindexed, но позиции
массивов от начала переменной задаются не в количестве ячеек
базового типа, а в байтах.
MPI_Type_struct : создает описатель структуры. Наверняка будет использоваться Вами чаще всего.
MPI_Type_struct(
count, /* количество полей */
int *len, /* массив с длинами полей */
/* (на тот случай, если это массивы) */
MPI_Aint *pos, /* массив со смещениями полей */
/* от начала структуры, в байтах */
MPI_Datatype *types, /* массив с описателями типов полей */
MPI_Datatype *newtype ); /* ссылка на создаваемый тип */
Здесь используется тип MPI_Aint: это просто скалярный тип, переменная которого имеет одинаковый с указателем размер. Введен он исключительно для единообразия с Фортраном, в котором нет типа "указатель". По этой же причине имеется и функция MPI_Address: в Си она не нужна (используются оператор вычисления адреса & и основанный на нем макрос offsetof() ); а в Фортране оператора вычисления адреса нет, и используется MPI_Address.
Пример создания описателя типа "структура":
#include <stddef.h> /* подключаем макрос 'offsetof()' */
typedef struct {
int i;
double d[3];
long l[8];
char c;
} AnyStruct;
AnyStruct st;
MPI_Datatype anyStructType;
int len[5] = { 1, 3, 8, 1, 1 };
MPI_Aint pos[5] = { offsetof(AnyStruct,i), offsetof(AnyStruct,d),
offsetof(AnyStruct,l), offsetof(AnyStruct,c),
sizeof(AnyStruct) };
MPI_Datatype typ[5] = { MPI_INT,MPI_DOUBLE,MPI_LONG,MPI_CHAR,MPI_UB };
MPI_Type_struct( 5, len, pos, typ, &anyStructType );
MPI_Type_commit( &anyStructType );
/* подготовка закончена */
MPI_Send( st, 1, anyStructType, ... );
Обратите внимание: структура в примере содержит 4 поля, а массивы
для ее описания состоят из 5 элементов. Сделано это потому, что MPI
должен знать не только смещения полей, но и размер всей структуры.
Для этого и служит псевдотип MPI_UB ("upper bound").
Адрес начала структуры и адрес ее первого поля, как правило, совпадают,
но если это не так: нулевым элементом массива typ должен быть MPI_LB.
MPI_Type_extent и MPI_Type_size : важные информационные функции. Их характеристики удобно представить в виде таблицы:
| Вид данных | sizeof | MPI_Type_extent | MPI_type_size |
|---|---|---|---|
| стандартный тип | равносильны | ||
| массив | равносильны | ||
| структура | равносильны | sizeof(поле1)+sizeof(поле2)+... | |
| Описатель типа MPI с перекрытиями и разрывами | не определена | адрес последней ячейки данных - адрес первой ячейки данных + sizeof(последней ячейки данных) | sizeof(первой ячейки данных) + sizeof(второй ячейки данных) + ... |
Можно сказать, что MPI_Type_extent сообщает, сколько места
переменная типа занимает при хранении в памяти, а MPI_Type_size -
какой МИНИМАЛЬНЫЙ размер она будет иметь при передаче (ужатая
за счет неиспользуемого пространства). MPI_Type_size отсутствует
в примере, потому что закомментирована
в WinMPICH - в binding.h сказано, что стандарт на нее сформулирован
неправильно.
В Фортране их придется использовать постоянно ввиду отсутствия
sizeof (в Фортране чего не хватишься - того и нет).
Под термином "коллективные" в MPI подразумеваются три группы функций:
Коллективная функция одним из аргументов получает описатель области связи (коммуникатор). Вызов коллективной функции является корректным, только если произведен из всех процессов-абонентов соответствующей области связи, и именно с этим коммуникатором в качестве аргумента (хотя для одной области связи может иметься несколько коммуникаторов, подставлять их вместо друг друга нельзя). В этом и заключается коллективность: либо функция вызывается всем коллективом процессов, либо никем; третьего не дано.
Как поступить, если требуется ограничить область действия для коллективной функции только частью присоединенных к коммуникатору задач, или наоборот - расширить область действия? Создавайте временную группу/область связи/коммуникатор на базе существующих, как это показано в разделе про коммуникаторы.
Этим занимается всего одна функция:
int MPI_Barrier( MPI_Comm comm );
MPI_Barrier останавливает выполнение вызвавшей ее задачи до тех пор, пока не будет вызвана изо всех остальных задач, подсоединенных к указываемому коммуникатору. Гарантирует, что к выполнению следующей за MPI_Barrier инструкции каждая задача приступит одновременно с остальными.
Это единственная в MPI функция, вызовами которой гарантированно синхронизируется во времени выполнение различных ветвей! Некоторые другие коллективные функции в зависимости от реализации могут обладать, а могут и не обладать свойством одновременно возвращать управление всем ветвям; но для них это свойство является побочным и необязательным - если Вам нужна синхронность, используйте только MPI_Barrier.
Когда может потребоваться синхронизация? В примерах синхронизация используется перед аварийным завершением: там ветвь 0 рапортует об ошибке, и чтобы ни одна из оставшихся ветвей вызовом MPI_Abort не завершила нулевую досрочно-принудительно, перед MPI_Abort поставлен барьер.
Это утверждение непроверено, но: АЛГОРИТМИЧЕСКОЙ необходимости в барьерах, как представляется, нет. Параллельный алгоритм для своего описания требует по сравнению с алгоритмом классическим всего лишь двух дополнительных операций - приема и передачи из ветви в ветвь. Точки синхронизации несут чисто технологическую нагрузку вроде той, что описана в предыдущем абзаце.
Иногда случается, что ошибочно работающая программа перестает врать, если ее исходный текст хорошенько нашпиговать барьерами. Как правило, барьерами нивелируются ошибки под кодовым названием "гонки" (в англоязычной литературе используется термин "backmasking"; я НЕ уверен, что под этими терминами понимается строго одно и то же). Однако программа начнет работать медленнее, например:
ветвь
Без барьеров: 0 xxxx....xxxxxxxxxxxxxxxxxxxx
1 xxxxxxxxxxxx....xxxxxxxxxxxx
2 xxxxxxxxxxxxxxxxxxxxxx....xx
Воткнем барьеры: 0 xxxx....xx(xxxxxxxx(||||xxxxxxxx(||xx
1 xxxxxx(||||x....xxxxxxx(xxxxxxxx(||xx
2 xxxxxx(||||xxxxxxxx(||||..xxxxxxxx(xx
----------------------------- > Время
Обозначения:
x нормальное выполнение
. ветвь простаивает - процессорное время отдано под другие цели
( вызван MPI_Barrier
| MPI_Barrier ждет своего вызова в остальных ветвях
Так что "задавить" ошибку барьерами хорошо только в качестве временного решения на период отладки.
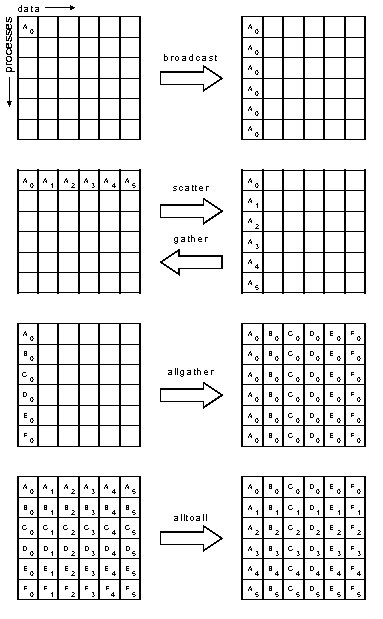
MPI_Bcast рассылает содержимое буфера из задачи, имеющей в указанной области связи номер root, во все остальные:
MPI_Bcast( buf, count, dataType, rootRank, communicator );
Она эквивалентна по результату (но не по внутреннему устройству) следующему фрагменту:
MPI_Comm_size( communicator, &commSize );
MPI_Comm_rank( communicator, &myRank );
if( myRank == rootRank )
for( i=0; i<commSize; i++ )
MPI_Send( buf, count, dataType, i,
tempMsgTag, communicator );
MPI_Recv( buf, count, dataType, rootRank, tempMsgTag,
communicator, &status );
MPI_Gather ("совок") собирает в приемный буфер задачи root передающие буфера остальных задач. Ее аналог:
MPI_Send( sendBuf, sendCount, sendType, rootRank, ... );
if( myRank == rootRank ) {
MPI_Type_extent( recvType, &elemSize );
for( i=0; i<commSize; i++ )
MPI_Recv( ((char*))recvBuf) + (i * recvCount * elemSize),
recvCount, recvType, i, ... );
}
Заметьте, что а) recvType и sendType могут быть разные и, таким образом,
будут задавать разную интерпретацию данных на приемной и передающей
стороне; б) задача-приемник также отправляет данные в свой приемный буфер.
Векторный вариант "совка" - MPI_Gatherv - позволяет задавать РАЗНОЕ количество отправляемых данных в разных задачах-отправителях. Соответственно, на приемной стороне задается массив позиций в приемном буфере, по которым следует размещать поступающие данные, и максимальные длины порций данных от всех задач. Оба массива содержат позиции/длины НЕ в байтах, а в количестве ячеек типа recvCount. Ее аналог:
MPI_Send( sendBuf, sendCount, sendType, rootRank, ... );
if( myRank == rootRank ) {
MPI_Type_extent( recvType, &elemSize );
for( i=0; i<commSize; i++ )
MPI_Recv( ((char*))recvBuf) + displs[i] * recvCounts[i]
* elemSize, recvCounts[i], recvType, i, ... );
}
MPI_Scatter ("разбрызгиватель") : выполняет обратную "совку" операцию - части передающего буфера из задачи root распределяются по приемным буферам всех задач. Ее аналог:
if( myRank == rootRank ) {
MPI_Type_extent( recvType, &elemSize );
for( i=0; i<commSize; i++ )
MPI_Send( ((char*)sendBuf) + i*sendCount*elemSize,
sendCount, sendType, i, ... );
}
MPI_Recv( recvBuf, recvCount, recvType, rootRank, ... );
И ее векторный вариант - MPI_Scatterv, рассылающая части неодинаковой длины в приемные буфера неодинаковой длины.
MPI_Allgather аналогична MPI_Gather, но прием осуществляется не в одной задаче, а во ВСЕХ: каждая имеет специфическое содержимое в передающем буфере, и все получают одинаковое содержимое в буфере приемном. Как и в MPI_Gather, приемный буфер последовательно заполняется данными изо всех передающих. Вариант с неодинаковым количеством данных называется MPI_Allgatherv.
MPI_Alltoall : каждый процесс нарезает передающий буфер на куски и рассылает куски остальным процессам; каждый процесс получает куски от всех остальных и поочередно размещает их приемном буфере. Это "совок" и "разбрызгиватель" в одном флаконе. Векторный вариант называется MPI_Alltoallv.
Пример использования коллективных функций передачи данных здесь.
В учебнике, изданном MIT Press, есть хорошая СХЕМА для всех перечисленных в этом разделе функций. Понять, что как работает, по ней нелегко, зато вспоминать, если однажды уже разобрался, удобно.
Помните, что коллективные функции несовместимы с "точка-точка": недопустимым, например, является вызов в одной из принимающих широковещательное сообщение задач MPI_Recv вместо MPI_Bcast.
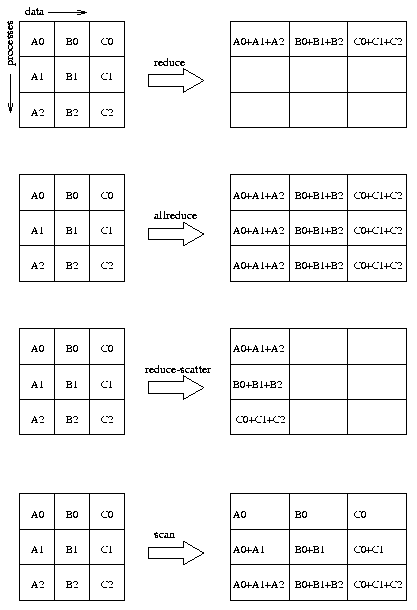
Идея проста: в каждой задаче имеется массив. Над нулевыми ячейками всех массивов производится некоторая операция (сложение/произведение/ поиск минимума/максимума и т.д.), над первыми ячейками производится такая же операция и т.д. Четыре функции предназначены для вызлва этих операций и отличаются способом размещения результата в задачах.
MPI_Reduce : массив с результатами размещается в задаче с номером root:
int vector[16];
int resultVector[16];
MPI_Comm_rank( MPI_COMM_WORLD, &myRank );
for( i=0; i<16; i++ )
vector[i] = myRank*100 + i;
MPI_Reduce(
vector, /* каждая задача в коммуникаторе предоставляет вектор */
resultVector, /* задача номер 'root' собирает данные сюда */
16, /* количество ячеек в исходном и результирующем массивах */
MPI_INT, /* и тип ячеек */
MPI_SUM, /* описатель операции: поэлементное сложение векторов */
0, /* номер задачи, собирающей результаты в 'resultVector' */
MPI_COMM_WORLD /* описатель области связи */
);
if( myRank==0 )
/* печатаем resultVector, равный сумме векторов */
Предопределенных описателей операций в MPI насчитывается 12:
Естественный вопрос: а с массивами каких типов умеют работать эти функции? Ответ приводится в виде таблицы:
| Операция | Допустимый тип операндов |
|---|---|
| MPI_MAX, MPI_MIN | целые и вещественные |
| MPI_SUM, MPI_PROD | целые, вещественные, комплексные |
| MPI_LAND, MPI_LOR, MPI_LXOR | целые и логические |
| MPI_LAND, MPI_LOR, MPI_LXOR | целые (в т.ч. байтовые) |
Этим типам операндов могут соответствовать следующие описатели:
| Тип | Описатель в Си | Описатель в Фортране |
|---|---|---|
| целый | MPI_INT, MPI_UNSIGNED_INT, MPI_LONG, MPI_UNSIGNED_LONG, MPI_SHORT, MPI_UNSIGNED_SHORT | MPI_INTEGER |
| целый байтовый | MPI_BYTE | (нет) |
| вещественный | MPI_FLOAT, MPI_DOUBLE, MPI_LONG_DOUBLE | MPI_REAL, MPI_DOUBLE_PRECISION |
| логический | (нет, пользуйтесь типом int) | MPI_LOGICAL |
| Комплексный | (нет) | MPI_COMPLEX |
Количество поддерживаемых операциями типов для ячеек векторов строго ограничено вышеперечисленными. Никакие другие встроенные или пользовательские описатели типов использоваться не могут! Обратите также внимание, что все операции являются ассоциативными ( "(a+b)+c = a+(b+c)" ) и коммутативными ( "a+b = b+a" ).
MPI_Allreduce : результат рассылается всем задачам, параметр 'root' убран.
MPI_Reduce_scatter : каждая задача получает не весь массив-результат, а его часть. Длины этих частей находятся в массиве-третьем параметре функции. Размер исходных массивов во всех задачах одинаков и равен сумме длин результирующих массивов.
MPI_Scan : аналогична функции MPI_Allreduce в том отношении, что каждая задача получает результрующий массив. Главное отличие: здесь содержимое массива-результата в задаче i является результатом выполнение операции над массивами из задач с номерами от 0 до i включительно.
В упоминавшейся уже книге распределенные операции иллюстрирует соответствующая СХЕМА
Помимо встроенных, пользователь может вводить свои собственные операции, но механизм их создания здесь не рассматривается. Для этого служат функции MPI_Op_create и MPI_Op_free, а также тип MPI_User_function.
Группа - это некое множество ветвей. Одна ветвь может быть членом нескольких групп. В распоряжение программиста предоставлен тип MPI_Group и набор функций, работающих с переменными и константами этого типа. Констант, собственно, две: MPI_GROUP_EMPTY может быть возвращена, если группа с запрашиваемыми характеристиками в принципе может быть создана, но пока не содержит ни одной ветви; MPI_GROUP_NULL возвращается, когда запрашиваемые характеристики противоречивы. Согласно концепции MPI, после создания группу нельзя дополнить или усечь - можно создать только новую группу под требуемый набор ветвей на базе существующей.
Область связи ("communication domain") - это нечто абстрактное: в распоряжении программиста нет типа данных, описывающего непосредственно области связи, как нет и функций по управлению ими. Области связи автоматически создаются и уничтожаются вместе с коммуникаторами. Абонентами одной области связи являются ВСЕ задачи либо одной, либо двух групп.
Коммуникатор, или описатель области связи - это
верхушка трехслойного пирога (группы, области связи, описатели
областей связи), в который "запечены" задачи: именно
с коммуникаторами программист имеет дело, вызывая функции
пересылки данных, а также подавляющую часть вспомогательных функций.
Одной области связи могут соответствовать несколько коммуникаторов.
Коммуникаторы являются "несообщающимися сосудами": если
данные отправлены через один коммуникатор, ветвь-получатель
сможет принять их только через этот же самый коммуникатор,
но ни через какой-либо другой.
Зачем вообще нужны разные группы, разные области связи и разные их описатели?
Коммуникаторы распределяются автоматически (функциями семейства "Создать новый комуникатор"), и для них не существует джокеров ("принимай через какой угодно коммуникатор") - вот еще два их существенных достоинства перед идентификаторами сообщений. Идентификаторы (целые числа) распределяются пользователем вручную, и это служит источником двух частых ошибок вследствие путаницы на приемной стороне:
Важно помнить, что ВСЕ функции, создающие коммуникатор, являются КОЛЛЕКТИВНЫМИ! Именно это качество позволяет таким функциям возвращать в разные ветви ОДИН И ТОТ ЖЕ описатель. Коллективность, напомню, заключется в следующем:
Копирование. Самый простой способ создания коммуникатора - скопировать "один-в-один" уже имеющийся:
MPI_Comm tempComm;
MPI_Comm_dup( MPI_COMM_WORLD, &tempComm );
/* ... передаем данные через tempComm ... */
MPI_Comm_free( &tempComm );
Новая группа при этом не создается - набор задач остается прежним.
Новый коммуникатор наследует все свойства копируемого.
См. также пример 6
Расщепление. Соответствующая коммуникатору группа расщепляется на непересекающиеся подгруппы, для каждой из которых заводится свой коммуникатор.
MPI_Comm_split(
existingComm, /* существующий описатель, например MPI_COMM_WORLD */
indexOfNewSubComm, /* номер подгруппы, куда надо поместить ветвь */
rankInNewSubComm, /* желательный номер в новой подгруппе */
&newSubComm ); /* описатель области связи новой подгруппы */
Эта функция имеет одинаковый первый параметр во всех ветвях, но разные
второй и третий - и в зависимости от них разные ветви определяются
в разные подгруппы; возвращаемый в четвертом параметре описатель
будет принимать в разных ветвях разные значения (всего столько разных
значений, сколько создано подгрупп). Если indexOfNewSubComm равен
MPI_UNDEFINED, то в newSubComm вернется MPI_COMM_NULL,
то есть ветвь не будет включена ни в какую из созданных групп.
См. также пример 7
Создание через группы. В предыдущих двух случаях коммуникатор создается от существующего коммуникатора напрямую, без явного создания группы: группа либо та же самая, либо создается автоматически. Самый же общий способ таков:
Может ли задача обратиться к области
связи, абонентом которой не является?
Нет. Описатель области связи передается в задачу функциями MPI,
которые одновременно делают эту задачу абонентом описываемой области.
Таков единственный существующий способ получить описатель.
Попытки "пиратскими" средствами обойти это препятствие
(например, получить описатель, посредством MPI_Send/MPI_Recv
переслать его в другую задачу, не являющуюся его абонентом,
и там им воспользоваться) не приветствуются, и исход их,
скорее всего, будет определяться деталями реализации.
Помимо характеристик области связи, тело коммуникатора содержит в себе некие дополнительные данные (атрибуты). Механизм хранения атрибутов называется "caching". Атрибуты могут быть системные и пользовательские; в системных, в частности, хранятся:
Атрибуты идентифицируются целыми числами, которые MPI назначает автоматически. Некоторые константы для описания системных атрибутов: MPI_TAG_UB, MPI_HOST, MPI_IO, MPI_WTIME_IS_GLOBAL. К этим атрибутам программист обращается редко, и менять их не может; а для таких часто используемых атрибутов, как обработчик ошибок или описание топологии, существуют персональные наборы функций, например, MPI_Errhandler_xxx.
Атрибуты - удобное место хранения совместно используемой информации; помещенная в атрибут одной из ветвей, такая информация становится доступной всем использующим коммуникатор ветвям БЕЗ пересылки сообщений (вернее, на MPP-машине, к примеру, сообщения будут, но на системном уровне, т.е. скрытые от глаз программиста).
Пользовательские атрибуты создаются и уничтожаются функциями
MPI_Keyval_create и MPI_Keyval_free; модифицируются
функциями MPI_Attr_put, MPI_Attr_get и MPI_Attr_delete.
При создании коммуникатора на базе существующего атрибуты
из последнего тем или иным образом копируются или нет
в зависимости от функции копирования типа MPI_Copy_function,
адрес которой является параметром функции создания атрибута.
То же и для удаления атрибутов при уничтожении коммуникатора:
задается пользовательской функцией типа MPI_Delete_function,
указываемой при создании атрибута.
Здесь имеются в виду ВСЕ типы системных данных, для которых предусмотрена функция MPI_Xxx_free (и константа MPI_XXX_NULL). В MPI-I их 7 штук ( можете посчитать сами, посмотрев в mpi.h ):
Не играет роли, в каком порядке уничтожать взаимосвязанные описатели. Главное - не забыть вызвать функцию удаления ресурса MPI_Xxx_free вовсе. Соответствующий ресурс не будет удален немедленно, он прекратит существование только если будут выполнены два условия:
Взаимосвязанными описателями являются описатели коммуникатора и группы (коммуникатор ссылается на группу); или описатели типов, если один создан на базе другого (порожденный ссылается на исходный).
Пример:
MPI_Comm subComm;
MPI_Group subGroup;
int rank;
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_split( MPI_COMM_WORLD, rank / 3, rank % 3, &subComm );
/* Теперь создан коммуникатор subComm, и автоматически создана
* группа, на которую распространяется его область действия.
* На коммуникатор заведена ссылка из программы - subComm.
* На группу заведена системная ссылка из коммуникатора.
*/
MPI_Comm_group( subComm, &subGroup );
/* Теперь на группу имеется две ссылки - системная
* из коммуникатора, и пользовательская subGroup.
*/
MPI_Group_free( &subGroup );
/* Пользовательская ссылка на группу уничтожена,
* subGroup сброшен в MPI_GROUP_NULL.
* Собственно описание группы из системных данных не удалено,
* так как на него еще ссылается коммуникатор.
*/
MPI_Comm_free( &subComm );
/* Удалена пользовательская ссылка на коммуникатор,
* subComm сброшен в MPI_COMM_NULL. Так как других ссылок
* на коммуникатор нет, его описание удаляется из системных данных.
* Вместе с коммуникатором удалена системная ссылка на группу.
* Так как других ссылок на группу нет, ее описание удаляется
* из системных данных.
*/
Еще раз: для MPI не играет роли, в каком порядке будут вызваны
завершающие вызовы MPI_Xxx_free, это дело программы.
И не пытайтесь уничтожать константные описатели вроде MPI_COMM_WORLD или MPI_CHAR: их создание и уничтожение - дело самого MPI.
Интеркоммуникаторы и интрaкоммуникаторы: описатели областей связи соответственно над двумя группами или над одной. MPI_COMM_WORLD является интрАкоммуникатором. Интер-коммуникаторы не являются предметом первой необходимости для новичка, поэтому за пределами данного абзаца упоминаний о них нет. Все упомянутые в документе функции, оперирующие коммуникаторами, либо не различают "интра-" и "интер-" вовсе, либо явно требуют "интра-". К числу последних относятся:
Пользовательские топологии. Внутри группы задачи пронумерованы линейно от 0 до (размер группы-1). Однако через коммуникатор можно ДОПОЛНИТЕЛЬНО навязать для них еще одну систему нумерации. Таких дополнительных систем в MPI две: картезианская n-мерная решетка (с цикличностью и без оной), а также биориентированный граф. Предоставляются функции для создания нумераций (MPI_Topo_test, MPI_Cart_xxx, MPI_Graph_xxx) и для преобразования номеров из одной системы в другую. Этот механизм не должен восприниматься как предоставляющий возможность подгонки связей между ветвями под аппаратную топологию для повышения быстродействия - он всего лишь автоматизирует перерасчет адресов, которым должны заниматься ветви, скажем, при вычислении матриц: через коммуникатор задается картезианская система координат, где координаты ветви совпадают с координатами вычисляемой ею подматрицы.
Обработчики ошибок. По умолчанию, если при выполнеии функции MPI обнаружена ошибка, выполнение всех ветвей приложения завершается. Это сделано в расчете на неряшливого программиста, не привыкшего проверять коды завершения (malloc,open,write,...;), и пытающегося распространить такой стиль на MPI. При аварийном завершении по такому сценарию на консоль выдается очень скудная информация: в лучшем случае, там будет название функции MPI и название ошибки. Обработчик ошибок является принадлежностью коммуникатора, для управления обработчиками служат функции семейства MPI_Errhandler_xxx. Пример написания собственного обработчика, выводящего более полную диагностику, находится здесь, краткое русское описание - здесь.
Многопоточность. Сам MPI неявно использует многопоточность очень широко, и не мешает программисту делать то же самое. Однако: разные задачи имеют с точки зрения MPI ОБЯЗАТЕЛЬНО разные номера, а разные потоки (threads) внутри одной задачи для него ничем не отличаются. Программист сам идентификаторами сообщений и коммуникаторами должен устанавливать такую дисциплину для потоков, чтобы один поток не стал, допустим, вызывая MPI_Recv, джокером перехватывать сообщения, которые должен принимать и обрабатывать другой поток той же задачи. Другим источником ошибок может быть использование разными потоками коллективных функций над одним и тем же коммуникатором: используйте MPI_Comm_dup !
Работа с файлами. В MPI-2 средства перенаправления работы с файлами появились, в MPI-1 их нет. Все вызовы функций напрямую передаются операционной системе (Unix/Parix/NFS/...) на той машине, или на том процессорном узле MPP-компьютера, где находится вызывающая ветвь. Теоретически возможность подключения средств расширенного управления вводом/выводом в MPI-1 есть - каждый коммуникатор хранит атрибут с числовым кодом MPI_IO - это номер ветви, в которую перенаправляется ввод/вывод от всех остальных ветвей в коммуникаторе; сам MPI ничего с ним не делает и никак не использует. Для MPI существует ряд дополнительных библиотек такого рода, как для конкретных платформ, так и свободно распространяемые многоплатформенные, но я не видел ни одной.
Работа с консолью также отдается на откуп системе; это может приводить к перемешиванию вывода нескольких задач, поэтому рекомендуется весь вывод на экран производить либо из какой-то одной задачи (нулевой?), либо в начале функции main() написать:
setvbuf( stdout, NULL, _IOLBF, BUFSIZ );
setvbuf( stderr, NULL, _IOLBF, BUFSIZ );
и не забудьте написать "#include <stdio.h>" в начале программы...



|
Закладки на сайте Проследить за страницей |
Created 1996-2026 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |
{kind=link}
{kind=link}