Мониторинг Windows серверов с помощью Nagios
Бешков Андрей
tigrisha@sysadmins.ru
Опубликовано в журнале "Системный администратор"
С момента публикации первой статьи о Nagios прошло довольно много времени, но вопросы и пожелания все продолжают приходить. Самый часто встречающийся вопрос как настроить слежение за серверами, работающими под управлением семейства операционных систем Windows. В этой статье мы рассмотрим два способа, используя которые можно добиться осуществления наших желаний.
Как всегда система мониторинга Nagios работает под управлением моей любимой системы FreeBSD 4.7. Приверженцы Linux, Solaris и других Unix-подобных систем тоже не останутся в стороне. Все описанные ниже приемы с незначительными изменениями можно с успехом применять и в их системах. В качестве подопытной системы будет использоваться русская версия Windows 2000 Professional. Такой выбор обусловлен тем фактом, что настроить программное обеспечение для исправной работы с русской версией сложнее, чем с аналогичной английской. Придется решать проблемы связанные с локализацией, а значит, статья получится гораздо полезнее и интереснее. Последовательность действий по настройке программного обеспечения выглядит практически одинаково для всех версий Windows. Я надеюсь, что никому из Вас не приходит в голову мысль серьезно рассматривать в качестве операционной системы для установки на сервер Windows 3.1, 3.11, 95, 98, ME. Поэтому дальше в этой статье о них не будет сказано ни слова, соответственно Вы можете с полным правом считать, что все методы, описанные ниже, работать с ними скорее всего не будут. Впрочем если есть желание можете проверить эти гипотезы лично.
В дальнейшем, предполагается, что Вы прочитали первую статью, подробно описывающую основы установки и настройки Nagios, либо в февральском номере журнала "Системный администратор", либо на моем сайте.
Покончив с формальностями, приступим к изучению конструкции и принципов работы подсистемы сбора данных о производительности. Такая система встроена в каждую Windows систему старше, чем Windows ME.
Для сбора статистики о своем функционировании Windows NT, Windows 2000, Windows XP используют объекты производительности. Делать подобные утверждения о Windows 2003 не буду, потому что потрогать ее пока не удалось. Каждый компонент системы в процессе работы генерирует данные о производительности и складывает их в счетчики (performance counters) собственного объекта производительности. На самом деле объект это абстракция, введенная для облегчения понимания материала. Логичнее всего было бы представлять объект как группу счетчиков связанную с наблюдаемой службой или ресурсом. Чаше всего название объекта совпадает с названием родительского системного компонента. В большинстве случаев объекты производительности соответствуют компонентам оборудования компьютера - память, процессор, жесткие диски. В тоже время, многие службы и программы могут создавать свои собственные объекты производительности. Иллюстрацией такого утверждения являются объекты службы "Обозреватель компьютеров" или серверной программы Internet Information Server. К примеру ,объект "Файл подкачки" содержит внутри себя набор счетчиков, говорящих о состоянии одного или нескольких файлов виртуальной памяти, используемых системой. Некоторые подсистемы имеют всего один экземпляр объекта производительности, другие же могут иметь несколько. К первому виду относятся "Система", "Память", "Сервер". "Жесткий диск" и "Процессор", соответственно, ко второму. Согласитесь, что жестких дисков в компьютере может быть несколько, а значит, внутри системы они должны быть представлены отдельными подсистемами. В тоже время, оперативная память, вне зависимости от количества, чипов является единым компонентом. А посему, иметь больше одного экземпляра объекта производительности ей не положено. В случае, если подсистема обладает несколькими экземплярами объекта, есть возможность следить за счетчиками всех экземпляров или за одним общим. В зависимости от языка операционной системы, объекты и счетчики называются по-разному. К примеру, посмотрим, как будет называться один и тот же счетчик в локализованных версиях Windows 2000:
| Название счетчика | Локализация |
| Committed Bytes | Английская |
| Byte vincolati | Итальянская |
| Zugesicherte Bytes | Немецкая |
| Байт выделенной виртуальной памяти | Русская |
| Octets dedies | Французская |
| Bytes comprometidos | Испанская |
| Bytes confirmados | Португальская |
По моему мнению, идеи более глупой, чем подобное чрезмерное увлечение локализацией, придумать нельзя. Представьте себе процесс написания программы, использующей в своей работе счетчики. Придется постоянно переделывать программу для каждой новой локализованной версии Windows. В дальнейшем все приводимые примеры будут опираться на русские версии перечисленных операционных систем семейства Windows.
Что бы закрепить все вышесказанное, давайте рассмотрим несколько примеров счетчиков:
\\TIGROID\Процессор(_Total)\% загруженности процессора
\\TIGROID\Процессор(0)\% загруженности процессора
\\TIGROID\Процессор(1)\% загруженности процессора
Первый компонент- это имя моего домашнего компьютера, на котором я пишу статьи и и провожу тестовые инсталяции. "Процессор" - названием объекта. Как Вы могли бы догадаться, (_Total) - экземпляр, инкапсулирующий внутри себя данные о производительности всех процессоров системы. Соответственно, (0) и (1)- экземпляры объектов первого и второго процессоров. И, наконец, "% загруженности процессора" - название самого счетчика. В повседневной практике сложилась традиция для краткости записывать названия счетчиков без имен компьютеров. Я считаю, что нам также стоит придерживаться ее.
Счетчики бывают следующих типов:
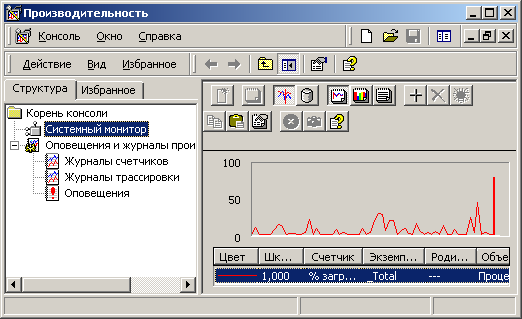
Существует возможность создавать счетчики других типов. Но для этого н еобходимо иметь пакет Platform Software Development Kit. Впрочем, обсуждение подобных методик выходит далеко за границы этой статьи. Просмотреть список объектов и счетчиков, существующих в системе, а также полюбоваться на их содержимое можно с помощью модуля "Монитор производительности", входящего в состав консоли управления Microsoft. А если говорить совсем просто, то открыть вышеописанный модуль можно, выполнив программу perfmon.exe. После ее запуска мы должны увидеть примерно такое окно.
Рассмотрим подробнее, что за чудо дизайна предстало перед нами. Слева мы видим дерево модуля, справа координатная плоскость для отображения графиков. Сверху у нас находится панель инструментов. Ну а внизу список счетчиков, используемых для построения графика. Для добавления еще одного счетчика в список нажимаем кнопку "+", находящуюся на панели инструментов.
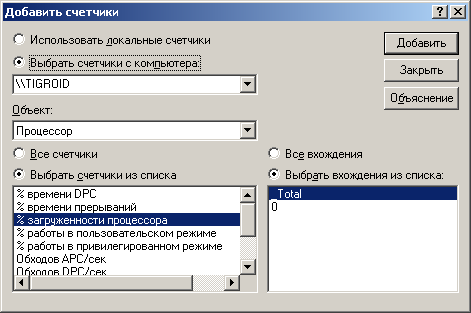
С помощью такого диалога можно просмотреть полный список счетчиков, объектов и их экземпляров, существующих в системе на данный момент. Для того, что бы узнать, как правильно называется тот или иной счетчик, добавьте его в список отображения. Очень полезно во время просмотра списка доступных счетчиков нажать кнопку "Объяснения", так как названия счетчиков недостаточно информативны. К примеру, как вам такой шедевр ясности с первого взгляда - "% времени DPC"? Ладно, оставим названия на совести создателей системы. Хотя если есть желание можно нажать кноку Объяснение и на экране появится маленькое окошко с кратким и не всегда понятным объяснением предназначения того или иного счетчика. Выбрав нужный счетчик, жмем кнопку "Добавить". Затем правой клавишей мыши щелкаем в центре графика и выбираем пункт меню "Свойства". В появившемся диалоговом окне наше внимание привлекает вкладка "Данные".
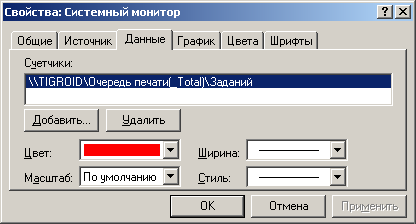
Теперь-то каждый из Вас сможет не только выбрать счетчики по вкусу, но и правильно записать их название. Ну а если самому от руки перепечатывать названия счетчиков в другие программы не охота то можно выполнить еще одну хитрость. Правой клавишей кликаем в центр графика и выбираем Сохранить как. В открывшемся диалоге вводим имя файла test.html и жмем Сохранить. Затем любым редактором открываем получившийся файл и среди кучи всяких ненужных данных ближе к концу файла видим полное и правильно написанное название счетчика. Затем с помощью буфера обмена его можно будет вставить в любую программу.
Вкратце обсудив принципы лежащие в основе сбора данных о производительности Windows машин, посмотрим, как можно с пользой для дела применять только что полученные знания.
Подопытная Windows машина называется win2000rus. Для начала давайте, выполним обязательные действия необходимые, для того чтобы Nagios узнал об этой машине. Делать это придется в любом случае вне зависимости от того какой способ мониторинга мы изберем. Поэтому внесем ее данные в файл hosts.cfg.
# Описываем хост по имени win2000rus
define host{
use generic-host
host_name win2000rus
alias Windows 2000 Russian
address win2000rus
check_command check-host-alive
max_check_attempts 10
notification_interval 120
notification_period 24x7
notification_options d,u,r
}
Теперь добавляем его в файл hostgroups.cfg описывающий группы хостов.
define hostgroup{
hostgroup_name win-servers
alias Windows Servers
contact_groups win-admins
members win2000rus
}
Создаем в файле contacts.cfg запись для человека, отвечающего за Windows сервера.
define contact{
contact_name serge
alias Sergei Petrov
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,u,r
service_notification_commands notify-by-email, notify-by-epager
host_notification_commands host-notify-by-email, host-notify-by-epager
email serge@test.ru
pager 172345885@pager.icq.com
}
Пожалуйста убедитесь что вы внесли группу контактов win-admins в файл contactgroups.cfg
define contactgroup{
contactgroup_name win-admins
alias Windows admins
members serge
}
Закончив с обязательными действиями перейдем к обсуждению первого способа мониторинга. Он состоит в том, чтобы установить на Windows машину программу NSClient, доставшуюся нам в наследство от проекта NetSaint. Запустившись как сервис, она начнет через каждые пять секунд читать содержимое определенных системных счетчиков Windows. Полученные величины записываются в круговой буфер, в котором хранятся данные за последние 24 часа. Занимаясь сбором статистики, программа ожидает входящие соединения от клиентов на 1248-й порт. Для считывания данных и передачи их серверу мониторинга будет использоваться программа check_nt из стандартной коллекции модулей Nagios.
Давайте посмотрим, какие именно сведения о функционировании подопытного Windows сервера можно получить с помощью check_nt:
Покончив с теорией, перейдем к инсталляции.
С сайта производителя берем последнюю версию программы NSClient. Я использовал версию 1.0.7.1. После распаковки дистрибутива должны появиться следующие директории:
| Название | Содержимое |
| LinuxBin | Исполняемые файлы для Linux |
| UnixSource | Исходный код для всех версий Unix |
| NTSource | Исходный код для всех версий Windows |
| Win_2k_XP_Bin | Исполняемые файлы для Windows 2000 и XP |
| Win_NT4_Bin | Исполняемые файлы для Windows NT |
Заглянув в директорию NTSource, понимаем - программа написана на Delphi. Впрочем, это обстоятельство никоим образом не мешает нам использовать ее для своих далеко идущих целей. Создаем директорию c:\Program Files\NSClient. Затем, в зависимости от установленной у нас операционной системы, копируем в нее содержимое либо из директории Win_2k_XP_Bin, либо из Win_NT4_Bin. Пользуясь следующими меню Пуск ->Выполнить запускаем командный интерпретатор cmd.exe. В появившемся окне набираем:
> C:\Program Files\NSClient\pNSClient /install
По окончанию установки система должна продемонстрировать нам подобное окошко.
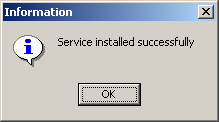
Это значит, программе удалось прописать себя в реестре подобающим образом. С помощью программы regedit откроем реестр. Ищем ветку \HKEY_LOCAL_MACHINE\SOFTWARE\NSClient\Params. Внутри расположились параметры password и port. Я думаю, предназначение каждого из них очевидно. Интуиция подсказывает мне - Вы согласитесь с утверждением, что возможность просматривать статистику должна быть предоставлена только программам, запущенным на сервере мониторинга. Меняем содержимое параметра password на что-нибудь длинное и трудно- подбираемое, например, "PxRT890mY".
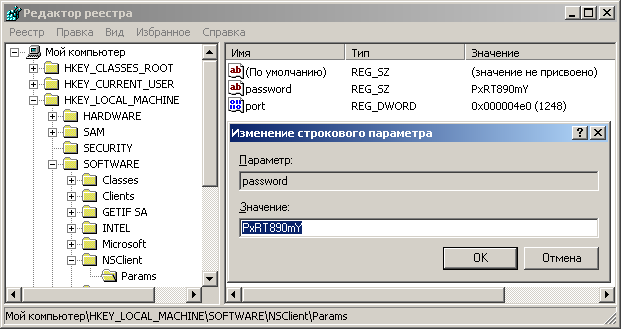
Теперь любой, кто попытается подключиться для получения данных на порт 1248, должен будет предъявить пароль.
Проверим, как себя чувствует наш новый сервис NetSaint NT agent. Выбираем следующие меню Пуск->Настройка->Панель управления. Затем дважды кликаем по пиктограмме "Администрирование", в открывшемся окне так же поступаем со значком "Службы". Должно получиться что-то подобное:
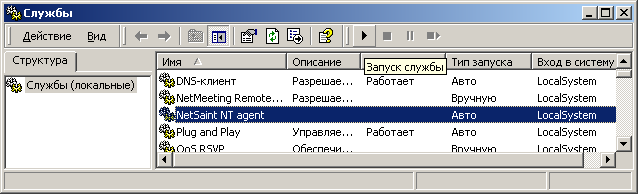
Нам нужно было увидеть следующую строку "NSClient 1.0.7.0 has started. Language code : 0x0419", опираясь на ее содержимое, мы можем узнать цифровой код языка, используемого в системе. Для русского языка это 0x0419, а для английского, соответственно, 0x0409. В файле C:\Program Files\NSClient\counters.defs находится описание системных счетчиков для всех известных программе языков. Просмотрев его до конца, понимаем, что кодом 0x0419 тут явно не пахнет. Отсюда вывод - для русской версии Windows получим дырку от бублика вместо статистики. Осознав, что такое несправедливое положение вещей нас не устраивает, добавляем в counters.defs новую секцию с названиями счетчиков, соответствующими нашему языку:
[0x0419]
Description = "Russian"
NT4_SystemTotalProcessorTime = "\Система\% загрузки процессора"
NT4_SystemSystemUpTime = "\Система\Время работы системы"
NT4_MemoryCommitLimit = "\Память\Предел выделенной виртуальной памяти"
NT4_MemoryCommitByte = "\Пямять\Байт выделенной виртуальной памяти"
W2K_SystemTotalProcessorTime = "\Процессор(_Total)\% загруженности процессора"
W2K_SystemSystemUpTime = "\Система\Время работы системы"
W2K_MemoryCommitLimit = "\Память\Предел выделенной виртуальной памяти"
W2K_MemoryCommitByte = "\Память\Байт выделенной виртуальной памяти"
Сохранив файл, перезапускаем сервис NetSaint NT agent. Тем, кому религия не позволяет вносить изменения в файлы собственноручно, предлагаю скачать модифицированную версию здесь http://onix.opennet.ru/files/. Еще раз бегло просматриваем журнал событий, дабы убедиться в отсутствии ошибок при перезапуске сервиса. Так же стоит удостовериться, что вся цепочка событий происходила в таком порядке:
NSClient is now responding to queries. NSClient 1.0.7.0 has started. Language code : 0x0419 NSClient is reading C:\Program Files\NSClient\counters.defs for counters definitions. Language code : 0x0419 NSClient has stopped
Закончив возню с Windows, переходим к Unix. В дальнейшем я предполагаю, что Nagios установлен в директорию /usr/local/nagios/. Запускается он с правами пользователя nagios, принадлежащего к группе nagios. По крайней мере, именно так это происходит во FreeBSD. Если Вы используете другую операционную систему, то вполне возможно настройки будут слегка отличаться. Для начала берем на сайте проекта Nagios самую свежую версию модулей. В моем случае это был файл nagiosplug-1.3-beta1.tar.gz. Распакуем архив
# tar zxvf nagiosplug-1.3-beta1.tar.gz
К сожалению, в официальном пакете модулей, подключаемых к Nagios, находится старая версия исходного текста программы check_nt. Если оставить все как есть, то некоторые функции сбора данных станут для нас недоступны. Сейчас мы легко в течение нескольких секунд устраним это досадное неудобство. Из дистрибутива, оставленного на Windows- машине, берем файл check_nt.c ,расположивщийся в директории UnixSource, и заменяем им старую версию, находящуюся на Unix-машине в директории ./nagiosplug-1.3-beta1/plugins/.
Осталось исправить еще одну ошибку. Она касается только тех, кто использует FreeBSD или Solaris. Открываем файл ./nagiosplug-1.3-beta1/plugins/utils.c и ищем там строку:
nchars = vsnprintf (str, size, fmt, ap);
Найдя, заменяем ее на вот это:
nchars = vsprintf (str, fmt, ap);
Если не выполнить исправления, то все результаты работы модуля check_nt будут выглядеть таким образом:
Memory usage: total:??????? Mb - used: ??????? Mb (???????%) - free: ??????? Mb (???????%) c:\ - total: ??????? Gb - used: ??????? Gb (???????%) - free ??????? Gb (???????%) CPU Load (1 min. 12???????
Смотрится такое сборище вопросов весьма забавно. Жаль, но для нас такие данные абсолютно бесполезны. После работы над ошибками, возвратившись в главную директорию дистрибутива, проводим конфигурирование, сборку и инсталляцию.
# cd .. # ./configure --prefix=/usr/local/nagios --with-nagios-user=nagios --with-nagios-grp=nagios # gmake all # gmake install
Стоит отметить тот факт, что для компиляции используется gmake вместо стандартной утилиты make. Иначе сборка сразу же после старта заканчивается сообщением о фатальной ошибке:
Making all in plugins /tmp/nagiosplug-1.3-beta1/plugins/Makefile, line 760: Need an operator make: fatal errors encountered cannot continue *** Error code 1
По завершению инсталляции, приступаем к созданию новых команд, пользуясь которыми Nagios будет собирать данные. Описание всех используемых команд должно располагаться в файле checkcommands.cfg. Формат этого файла довольно прост.
Каждая команда начинается с открывающего тега define command{. Затем с помощью ключевого слова command_name определяется имя команды. Следующая строка command_line определяет имя модуля вызываемого для осуществления проверки и параметры, передаваемые ему процессом Nagios. Особое внимание следует обратить на макросы подстановки значений $USER1$, $HOSTADDRESS$, $ARG1$, $ARG2$. Давайте посмотрим, зачем нужен каждый из них:
Завершается определение команды с помощью закрывающего тега }. Итак, приступим к разбору содержимого файла checkcommands.cfg.
# Описываем хост по имени win2000rus
# Определяем команду check_nt_cpuload . Использоваться она будет для
# сбора данных о загруженности процессора
define command{
command_name check_nt_cpuload
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v CPULOAD -l $ARG1$ -s $ARG2$
}
# Команда check_nt_memuse. Показывает данные об использовании памяти.
# Имеется в виду виртуальная память.
define command{
command_name check_nt_memuse
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v MEMUSE -w $ARG1$ -c $ARG2$ -s $ARG3$
}
# Команда check_nt_uptime. Отображает время работы системы
# с момента последней перезагрузки
define command{
command_name check_nt_uptime
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v UPTIME -s $ARG1$
}
# Команда check_nt_disk_space. Отображает размер свободного пространства
# на любом жестком диске системы
define command{
command_name check_nt_disk_space
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v USEDDISKSPACE -l $ARG1$ -w $ARG2$ -c $ARG3$ -s $ARG4$
}
# Описываем команду check_nt_service. Позволяет проверить, запущен ли
# опцию -d SHOWALL, позволяющую вывести более подробные
# диагностические сообщения.
define command{
command_name check_nt_service
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v SERVICESTATE -d SHOWALL -l $ARG1$ -s $ARG2$
}
# Самая простая из всех вышеописанных команд check_nt_client_version
# позволяет узнать версию программы NSClient., работающую в системе
define command{
command_name check_nt_client_version
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v CLIENTVERSION -s $ARG1$
}
# Команда check_nt_file_age дает возможность проверить время модификации
# любого файла на локальной машине
define command{
command_name check_nt_file_age
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v FILEAGE -l $ARG1$ -w $ARG2$ -c $ARG3$ -s $ARG4$
}
# Определяем команду check_nt_process. Предоставляет механизм, с помощью
# которого можно узнать, существует ли в системе тот или иной процесс.
# Обратите внимание на необязательную опцию -d SHOWALL, позволяющую
# вывести более подробные диагностические сообщения о состоянии процесса.
define command{
command_name check_nt_process
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v PROCSTATE -d SHOWALL -l $ARG1$ -s $ARG2$
}
# Команда check_nt_counter дает возможность просмотреть содержимое
# любого счетчика производительности, и поэтому является самой
# универсальной из всех описанных команд.
define command{
command_name check_nt_counter
command_line $USER1$/check_nt -H $HOSTADDRESS$ -v COUNTER -l $ARG1$ -w $ARG2$ -c $ARG3$ -s $ARG4$
}
После того, как с файлом команд покончено, перейдем к файлу сервисов. Детально формат этого файла рассматривался в первой статье о Nagios. Здесь мы только рассмотрим формат строчки check_command, напрямую связанной с обсуждавшимися ранее макросами, и $ARG1$ в частности.
check_command check_nt_process!"calc.exe,notepad.exe,mspaint.exe"!PxRT890mY
В приведенной выше строке check_command - ключевое слово, check_nt_process - название макрокоманды, описанной с файле checkcommands.cfg. Все параметры, передаваемые макросам $ARG1$, $ARG2$, $ARG3$ и так далее должны быть отделены друг от друга восклицательным знаком. Таким образом, выходит, что значение "calc.exe,notepad.exe,mspaint.exe" будет передано в $ARG1$, а пароль PxRT890mY в $ARG1$. Определившись с синтаксисом, переходим к файлу services.cfg:
# На нашем сервере работают несколько самодельных программ.
# Они должны выполняться круглосуточно, поэтому мы создали
# следующий сервис. Для примера будут использоваться общедоступные
# программы "Калькулятор", "Paint", "Блокнот", поставляющиеся
# с каждым дистрибутивом Windows
define service{
use generic-service
host_name win2000rus
service_description User Programs
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Обратите внимание на тот факт, что мы следим не за самими
# программами, а за их процессами в памяти. Имена процессов можно
# узнать с помощью встроенного в Windows стандартного диспетчера
# задач. Также стоит внимательно присмотреться к формату
# списка процессов.
check_command check_nt_process!"calc.exe,notepad.exe,mspaint.exe"!PxRT890mY
}
# Этот сервис показывает версию программы NSClient ,работающей в системе
define service{
use generic-service
host_name win2000rus
service_description NSClient Version
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Формат команды очень простой. В $ARG1$ передается пароль
check_command check_nt_client_version!PxRT890mY
}
# Каждый час удаленный сервер базы данных кладет в локальную
# папку общего доступа c:\upload\ файл update.dbf
# В этом файле находятся обновления базы данных
# Если время создания файла не меняется больше, чем 70 минут,
# значит, происходит что-то нехорошее, и нужно перейти в состояние
# предупреждения. В случае, когда нет изменений 90 минут, сервис
# переходит в критическое состояние.
define service{
use generic-service
host_name win2000rus
service_description File age
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Все пути к файлам должны содержать двойной символ "\"
check_command check_nt_file_age!"c:\\upload\\update.dbf"!70!90!PxRT890mY
}
# Этот сервис показывает количество свободной виртуальной памяти,
# которое вычисляется таким образом. NSClient читает
# содержимое счетчика "\Память\Предел выделенной виртуальной памяти"
# и делит его на 100.
# Так получается величина, показывающая, сколько байт памяти
# принимается за один процент.
# Затем данные из счетчика "\Память\Байт выделенной виртуальной памяти"
# делятся на количество байт в одном проценте. Так мы узнаем, сколько
# процентов занято. К счастью, лично заниматься подобными операциями
# нет необходимости. NSClient сделает все сам.
define service{
use generic-service
host_name win2000rus
service_description Free Memory
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Переход в состояние предупреждения происходит, если занято 70% памяти.
# Критический статус наступает, когда израсходовано 90% памяти
check_command check_nt_memuse!70%!90%!PxRT890mY
}
# Этот сервис позволяет увидеть загрузку процессора
define service{
use generic-service
host_name win2000rus
service_description CPU Load
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Переход в состояние предупреждения происходит, если занято 70% памяти.
# Критический статус наступает, когда израсходовано 90% памяти
check_command check_nt_memuse!70%!90%!PxRT890mY
}
# Время работы системы с момента последней перезагрузки.
define service{
use generic-service
host_name win2000rus
service_description Up time
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
check_command check_nt_uptime!PxRT890mY
}
# Проверяем, функционирует ли сервис MS SQL SERVER и
# самописный сервис vmxposman
define service{
use generic-service
host_name win2000rus
service_description Runing Services
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Проблема в том, что в программе управления сервисами Windows
# показывает полные названия сервисов, предназначенные для человека.
# Нам же нужно название, которое используется для внутренних нужд
# Windows. Узнать эту тайну можно либо посмотрев ветвь реестра
# HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services.,
# либо установив бесплатную утилиту 'Service Manager NT' ,
# доступную для скачивания по следующему адресу
# http://www-rnks.informatik.tu-cottbus.de/~fsch/english/nttols.htm
# Обратите внимание на тот факт, что по аналогии с процессами
# имена сервисов тоже можно перечислять через запятую.
check_command check_nt_service!"mssqlserver,vmxposman"
}
# Следим за количеством заданий, находящихся в очереди принтера
define service{
use generic-service
host_name win2000rus
service_description Print Queue
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Используя команду check_nt_counter, можно получить данные с любого счетчика.
# В данным случае - \Очередь печати(_Total)\Заданий
# Строка "%.0f job(s)" указывает модулю применить к результату преобразование
# к типу float и вывести число в формате с точностью ноль знаков после запятой.
# Затем к числу для наглядности добавляется строка "job(s)".
# Если Вам непонятно, что это значит - посмотрите документацию по функции
# printf ( ) языка С.
# Переход в состояние предупреждения происходит при накоплении 5
# заданий, а критический статус наступает, если их становится 10 и более.
check_command check_nt_counter!"\Очередь печати(_Total)\Заданий","%.0f job(s)"!5!10!PxRT890mY
}
# Проверяем процент использования файла подкачки
define service{
use generic-service
host_name win2000rus
service_description Paging File
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Тут мы снова используем check_nt_counter, хотя и немного другим способом.
# Строка "Usage %.2f %%" указывает модулю применить к результату преобразование
# к типу float и вывести число в формате с точностью два знака после запятой.
# Затем для наглядности приклеиваем спереди строку "Usage". Обратите внимание
# на двойной знак "%" в строке форматирования. Снова вспомнив хорошими словами
# функцию printf ( ) ,понимаем, что в результате из двух получится один символ "%".
# Переход в состояние предупреждения происходит при достижении уровня
# в 80 процентов, а критический статус наступает, если файл подкачки заполнен
# на 90 и более процентов.
check_command check_nt_counter!"\Файл подкачки(_Total)\% использования","Usage %.2f %%"!80%!90%!PxRT890mY
}
Стоит отметить тот факт, что названия счетчиков, используемых в определении двух последних сервисов, написаны русскими буквами в кодировке cp1251. Если нарушить это требование, то NSClient не сможет понять, чего мы хотим от него добиться, и будет возвращать заведомо неправильные данные. Кодировка cp1251 используется для записи текстов по умолчанию всеми русскими Windows- системами. Вот тут-то нас и поджидает проблема. Дело в том, что в большинстве Unix подобных систем для символов русского языка используется кодировка KOI8-R. Конечно, можно перенастроить консоль, на которой работаете под cp1251, но такой подход лично мне кажется неудобным. Поэтому я поступил гораздо проще. Используя FTP, перенес файл checkcommands.cfg на Windows-машину. Затем с помощью стандартного редактора "Блокнот" внес требуемые изменения. Сохранился, перенес файл обратно на Unix машину и заменил старую копию в /usr/local/nagios/etc/. В принципе, нужного результата можно добиться разными путями. Немного подумав, я решил сделать это другим более простым способом. Набрал все нужные русскоязычные надписи в формате koi8-r. Из пакетов установил несколько программ для конвертирования текстов в разные кодировки:
После тестирования выяснилось, что удобнее всего использовать утилиту ru-mtc. Для конвертирования нужно выполнить такую последовательность команд.
# cat checkcommands.cfg | mtc -f koi8 -t win 1251 > checkcommands.tmp # mv checkcommands.tmp checkcommands.cfg
Теперь осталось только заставить Nagios перечитать файлы конфигурации.
# /usr/local/etc/rc.d/nagios.sh restart
Убедившись в отсутствии ошибок, можно начать ставить разные садистские эксперименты по проверке того насколько надежно и оперативно система мониторинга реагирует на критические ситуации, происходящие на Windows машине. Например, для того чтобы посмотреть, как работает слежение за очередью принтера можно выключить питание принтера и отправить несколько заданий на печать. Впрочем, я думаю, вы и сами сможете придумать разные способы создать критические ситуации. Наигравшись вдоволь, можно переходить ко второму способу мониторинга который я опишу с следующей статье.
| Архив документации на OpenNet.ru / Раздел "Сети, протоколы, сервисы" | (Для печати) |
Автор: Бешков Андрей Юрьевич
Оригинал: onix.opennet.ru
Мониторинг Windows серверов с помощью Nagios и SNMP
Бешков Андрей
tigrisha@sysadmins.ru
Опубликовано в журнале "Системный администратор"
В дальнейшем, предполагается, что Вы прочитали статью, подробно описывающую основы установки и настройки Nagios. Если дела обстоят именно так то идем дальше. Так же стоит убедиться что Вы ознакомились со следующей статьей описывающей общую теорию сбора данных и первый способ настройки Nagios для слежения за серверами работающими под управлением семейства операционных систем Windows. Для достижения наших целей на контролируемую машину устанавливалась программа NSClient, а данные собирались с помощью модуля check_nt.
Сегодня мы изучим второй способ мониторинга. Для получения необходимых данных мы будем использовать SNMP (Simple Network Management Protocol). Большинство знаний, приобретенных после прочтения этой статьи, можно будет применить для настройки не только систем мониторинга на основе Nagios. Понимание принципов работы SNMP и практические навыки обращения с Windows в этом аспекте позволят передать нужные нам данные другим системам мониторинга, работающим с SNMP. Например, это могут быть mrtg, OpenNMS, Dec PolyCenter Network Manager, HP Open View, IBM AIX NetView/600 и любые другие программы обладающие подобной функциональностью.
Давайте кратко разберемся с принципами работы этого протокола. Внутри каждого из устройств, которыми можно управлять, находится программное обеспечение для работы с SNMP, называемое агентом. В свою очередь, программа, работающая на станции управления сетью, называется менеджером. Агент выступает посредником между внутренними структурами управляемого объекта и менеджером. Обычно взаимодействие происходит по инициативе менеджера и выглядит следующим образом. Менеджер отправляет запрос агенту. Тот его обрабатывает, собирает данные и отправляет их назад. В некоторых случаях агент может самостоятельно инициировать обмен данными. Обычно у агента должен быть список важных событий, о наступлении которых он обязан оповестить менеджера. Затем менеджер по своему усмотрению выполняет какие-либо действия в ответ на оповещение. Например, такими событиями могут быть выход из строя какого-либо компонента внутри наблюдаемого объекта, аварийная перезагрузка, вызванная потерей питания или любая другая критическая ситуация. Процедура оповещения в терминах протокола SNMP называется отправкой ловушки (SNMP Trap).
Для того, чтобы менеджер мог управлять самыми разными видами оборудования, фирмы- производители создали стандартную абстрактную модель, позволяющую получить доступ к внутренним данным оборудования. В модель включается минимум данных, необходимых для управления и контроля. Например, модель сетевого сервера печати может содержать в себе следующие данные:
Количество доступной информации впечатляет. Самой приятной изюминкой в реализации SNMP является тот факт, что все сложности по взаимодействию с реальным оборудованием ложатся на плечи агента, который, в свою очередь, предоставляет стандартный интерфейс доступа к данным оборудования. Таким образом, менеджер может легко общаться с агентами, созданными разными производителями оборудования. Для того, чтобы агент мог правильно описать оборудование, в которое он встроен, а менеджер - понять, о чем идет речь, они должны оба опираться на одну и ту же модель подконтрольного ресурса. Данные модели хранятся в базе данных управляющей информации - MIB (Management Information Base) - которая полностью описывает список доступных характеристик ресурса. Пользуясь ею, менеджер может узнать, какие сведения агент способен предоставить, что они означают и какими свойствами аппаратуры можно управлять. Повсеместно MIB принято представлять в виде древовидной структуры. Определенные части этого дерева являются обязательными для всех реализаций SNMP.
В тоже время производитель оборудования может встраивать внутрь этого дерева свои собственные поддеревья. Чаще всего они называются private. С помощью такого встраивания реализуется возможность получить доступ к функциям и данным, характерным только для этого оборудования. Для примера посмотрим на стандартный образец данных, используемых агентом SNMP, работающим на машине win2000rus.
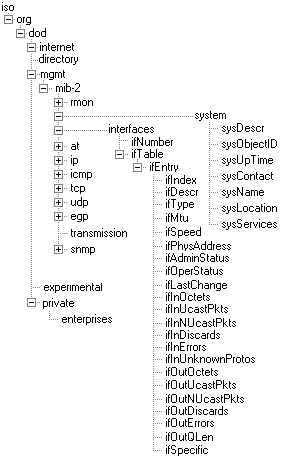
Например, для того чтобы узнать время работы системы с момента последней перезагрузки нужно пройти через ветку. iso.org.dod.internet.mgmt.mib2.system.sysUpTime. Буквенная запись используется для удобства человека, менеджеры и агенты оперируют числами. Соответственно, каждая часть пути имеет свой числовой идентификатор.
| Символьное обозначение | Цифровой идентификатор |
| iso | 1 |
| org | 3 |
| dod | 6 |
| internet | 1 |
| mgmt | 2 |
| mib2 | 1 |
| system | 1 |
| sysUpTime | 3 |
Это значит, что тот же самый путь выражается как .1.3.6.1.2.1.1.3. Если у Вас сегодня плохое настроение, то можно использовать подобное смешанное написание .iso.3.dod.1.mgmt.1.1.sysUpTime.
Выглядит странно, но от этого значение строки не меняется. В любом случае агент конвертирует его в числовое представление. Таким образом, мы получаем уникальную комбинацию чисел, однозначно идентифицирующую объект, находящийся в любой ветви древа. В дальнейшем такую комбинацию мы будем называть OID (Object identifier) или, говоря русским языком, "Идентификатор объекта".
В связи с тем, что префикс iso.org.dod.internet.mgmt.mib2 встречается почти в каждом OID, большинство людей вообще перестало его писать. Подразумевается наличие этого префикса, поэтому очень часто можно встретить такой вид записи system.sysUpTime.
Несмотря на то, что в каждой ветви дерева может находиться несколько экземпляров объектов, в некоторых находится только один. В этом случае все зависит о целесообразности. Например, нет смысла держать внутри ветви system.sysUpTime два экземпляра объекта, потому что время работы системы может быть только одно. В случае, если экземпляр объекта один, ему присваивается номер "0". Доступ к его данным можно получить, обратившись к нему либо как system.sysUpTime, либо system.sysUpTime.0.

Примером хранения нескольких экземпляров объекта являются ветви:
Внутри этих ветвей хранятся данные о сетевых картах, установленных на нашей машине. Подветвь interfaces обладает очень интересной конструкцией. Объект .interfaces.ifNumber содержит в себе цифру "2", это говорит нам, что в системе установлено две сетевые карты. Внутри ветви interfaces.ifTable.ifEntry находится массив данных сетевых интерфейсов. По сути дела это хэш массив. В некоторых книгах он еще называется ассоциативным массивом. Ветвь interfaces.ifTable.ifEntry.ifIndex объявляет два ключа с уникальными цифровыми идентификаторами. В дальнейшем эти ключи используются для того, чтобы не путать между собой экземпляры объектов внутри каждой нижележащей ветви. Таким образом, получается, что ко второй сетевой карте относятся следующие экземпляры объектов:
Ну а к первой сетевой карте относятся соответственно:
Разобравшись с форматом дерева, перейдем к операциям, которые можно выполнять с помощью SNMP.
Следующее интересное для нас понятие - "Имена Сообществ" (Community Names). Они являются своеобразным эквивалентом паролей и используются для того, чтобы разграничить, какие приказы агенту может отдавать тот или иной менеджер. Каждая из пяти перечисленных ранее операций должна содержать в себе правильное имя сообщества, иначе она не будет выполнена. Если агент настроен соответствующим образом, то в результате запроса с ошибочным именем сообщества менеджеру будет отправлена ловушка с жалобой на попытку ошибочной аутентификации. Имена сообществ бывают трех видов Read-Only, Read-Write и Trap. Если менеджер передает агенту команды GetRequest, GetNextRequest, то внутри должна быть та строка сообщества Read-Only которая запрограммирована в агенте.
Если же происходит попытка передать агенту на выполнение команду SetRequest, то для начала проверяется тип изменяемого объекта MIB. Тип должен быть read-write. И только затем происходит проверка переданного менеджером имени сообщества на совпадение со строкой Read-Write. Внесение изменений происходит, только если обе проверки завершились с положительным результатом.
В большинстве реализаций строка сообщества Trap применения не нашла. Первоначально она задумывалась как вспомогательное средство для облегчения процедуры сортировки внутри менеджера ловушек от разных видов агентов. Но, как показал опыт реальной эксплуатации протокола, необходимость в таких ухищрениях возникает очень редко.
SNMP работает на основе протокола UDP и для общения с сетью использует порт номер 162. Использование UDP в качестве основы означает, что данные передаются без установления соединения. Это дает возможность существенно уменьшить требования к сетевой инфраструктуре и накладные расходы на передачу данных. Пакеты SNMP могут передаваться также поверх ATM, Ethernet, IPX.
Одной из основных проблем с безопасностью протокола SNMP являются имена сообществ, установленные изготовителем оборудования по умолчанию. Многие производители используют в качестве имен всех перечисленных сообществ слово "public". Многие администраторы после установки оборудования напрочь забывают о необходимости сменить имена сообществ. В таком случае любой более или менее осведомленный о протоколе SNMP злоумышленник может получить доступ к важным функциям оборудования. Вторая большая проблема состоит в том, что пакеты протокола SNMP передаются через сеть открытым текстом. Получается, что узнать нужные строки сообществ не так уж и сложно. Подобное плачевное состояние с безопасностью протокола породило довольно забавную шутку. По мнению сетевых острословов, SNMP расшифровывается как "Security Not My Problem". Положение существенно улучшилось с введением второй версии протокола SNMP. Для противодействия злоумышленникам используются Symmetric Privacy Protocol (SPP), призванный защитить от прослушивания, и авторизация на основе Digest Authentication Protocol (DAP). Ну а до тех пор, пока SNMP v.2 не стал повсеместным стандартом, мы будем защищаться тем, что постараемся везде, где только возможно, перестать использовать команду SetRequest. Нам для проведения мониторинга совершенно нет необходимости ее применять. Таким образом, никто не сможет внести изменения в данные, находящиеся внутри оборудования. Еще одним способом борьбы со злоумышленниками должно стать запрещение пропускать пакеты протокола SNMP из Интернет во внутреннюю сеть. Так же необходимо жестко ограничить круг IP адресов менеджеров, которым позволено обращаться к агентам, находящимся внутри нашего оборудования. Если после прочтения этого краткого курса вам все еще непонятны какие-либо моменты теории работы SNMP, значит стоит почитать список часто задаваемых вопросов. Сделать это можно, передав любой поисковой машине запрос snmp faq. В случае, если такой помощи окажется недостаточно, стоит обратиться к документации, описывающей протокол. Лучшим источником таких сведений являются RFC 1156, 1213, 1157, 1146, 2571, 2574. Покончив с кратким обзором основ SNMP, перейдем к практическому применению полученных знаний.
Для того, чтобы на машине win2000rus заработала служба SNMP, нужно установить добавочные системные компоненты. Давайте пройдемся по цепочке меню Пуск->Настройка->Панель управления. Дважды кликнем пиктограмму "Установка и удаление программ". В открывшемся окне жмем кнопку "Добавление и удаление компонентов Windows".
Ставим галочку напротив "Средства управления и наблюдения".
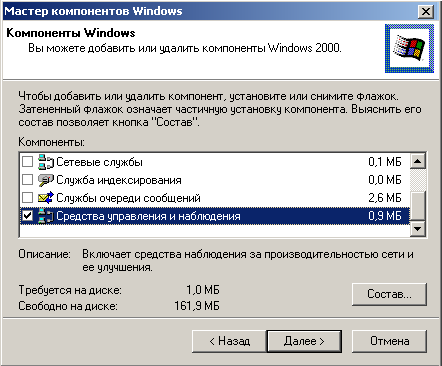
Нажимаем кнопку "Состав" и обязательно убеждаемся что "Протокол SNMP" тоже помечен галочкой.
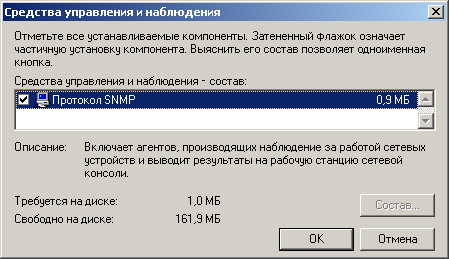
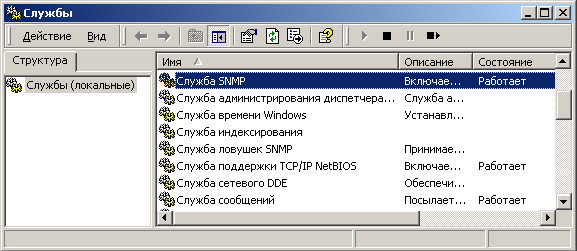
После нажатия кнопок "ОК" и "Далее" наблюдаем за процедурой инсталляции. По завершению оной посмотрим список служб, работающих на этой машине. "Служба SNMP" должна быть запущена. Исходя из того факта, что эта машина никогда не будет выступать в роли менеджера, и соответственно, ловушки ей слать никто не будет, сначала останавливаем, а затем и вовсе отключаем сервис "Служба ловушек SNMP".
Затем начинаем редактировать свойства службы SNMP. Сообщество Read-Only из public переименовываем в "QWEmn90" а сообщество Read-Wrie, скажем, в "Zxasd098".
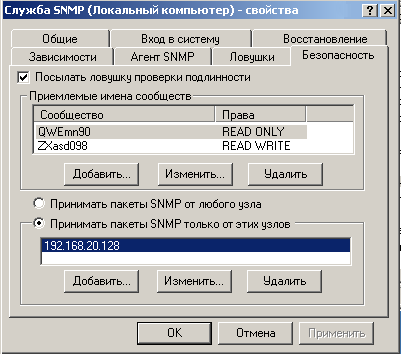
Заменив значения по умолчанию таким сложными для запоминания и случайного угадывания именами, мы повышаем безопасность использования SNMP. Честно говоря, сообщество Read-Write надежнее всего вообще отключить удалением соответствующего имени из списка. В список узлов, от которых можно принимать пакеты SNMP, добавляем адрес нашего сервера Nagios и самой Windows машины, тем самым выполняя еще один реверанс в сторону безопасности. Помня, что жизнь под Windows - это цепь постоянных перезагрузок, перезапускаем службу SNMP, для того чтобы изменения в настройках вступили в силу. Конечно можно было бы обойтись просто перезагрузкой службы SNMP, но полная перезагрузка машины все же будет надежнее.
Закончив с предварительным конфигурированием, побеспокоимся о своем удобстве. Установим на Windows машину браузер SNMP. Интерфейс командной строки - это хорошо, но все же графическими средствами бродить по веткам SNMP гораздо приятнее.
Для использования под Windows можно взять стандартный агент MS SMS Netmon на сайте производителя http://www.microsoft.com/smsmgmt/. Я буду использовать утилиту по имени GetIf версии 2.2, полученную тут http://www.wtcs.org/snmp4tpc/FILES/Tools/SNMP/getif/getif-2.2.zip. Она умеет делать много полезных вещей, но, самое главное, отлично работает с SNMP. У всех желающих есть возможность там же взять более современную версию 2.3. Хотя лично мне она не очень нравится из-за изменений в интерфейсе. В процессе инсталляции жмем несколько раз кнопку "Next". Не прошло и минуты, как мы стали счастливыми обладателями SNMP браузера. Для Unix - систем взять браузер можно здесь http://snmpbrowser.sourceforge.net/.
В дальнейшем все инструкции приводятся для работы с GetIf. Впрочем, остальные версии браузеров SNMP должны быть очень похожи в обращении. Запустим браузер первый раз и начнем заполнение полей необходимых для выполнения SNMP команд. В поле "Host Name" пишем адрес либо имя нашей Windows машины. Затем в поля "Read commuinty" и "Write community" вносим "QWEmn90" и "Zxasd098". Нажимаем кнопку "Start". Если все пустые строки заполнились данными, а не надписями "error" или "none" и получилось что-то подобное рисунку, значит SNMP работает исправно.
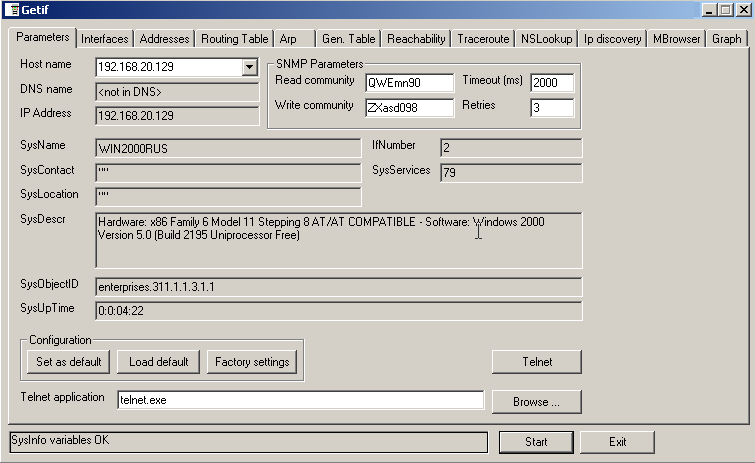
Теперь обратимся к вкладке MBrowser, ради возможностей которой все это собственно и затевалось. Для того, что бы получить данные, хранящиеся в какой-либо подветви, нужно дважды кликнуть на корневом элементе "iso". Возьмем, к примеру, OID iso.org.dod.internet.mgmt.mib-2.system.sysContact , содержащий описание системы. Пройдя через всю иерархию к нужной точке внутри дерева, нажимаем кнопку "Walk".
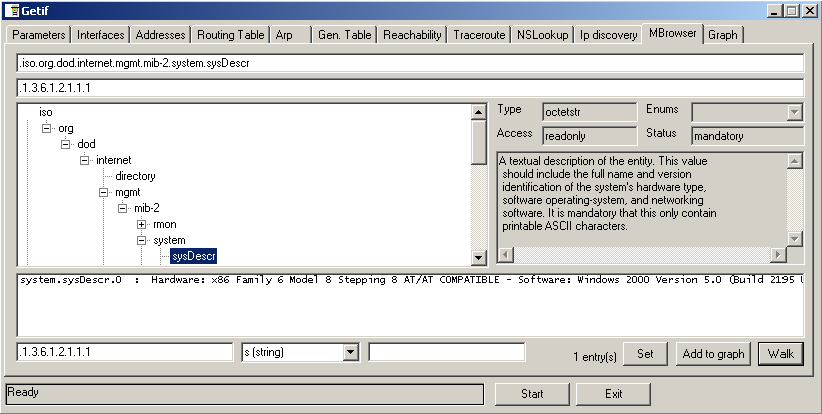
На экране должно отобразиться что-то подобное снимку приведенному выше. Давайте разберемся, что мы видим. Самое верхнее поле содержит символьную нотацию OID чуть ниже располагается цифровая форма записи того же самого. Еще ниже находится дерево MIB. Справа от дерева 4 информационных поля, описывающих выбранный объект. Среди них тип объекта (Type), доступ разрешаемый к объекту (Access), список значений, которые может принимать объект (Enums). Например, для OID, описывающего состояние сетевых интерфейсов .iso.org.dod.internet.mgmt.mib-2.IfTable.IfTable.IfEntry.IfOperStatus, доступны значения "up", "down", "testing". Затем идет статус объекта (Status) - является ли объект обязательным или нет. Еще ниже находится область, в которой выводится подробное разъяснение значения данных выбранного объекта. Хочу заметить, что, по моему мнению, это одна из самых полезных возможностей, предоставляемых браузером. Даже в символьной записи не всегда понятно, данные о какой функциональности устройства предоставляет та или иная ветвь дерева. Опускаясь еще немного вниз, видим окно, в котором отображаются результаты запросов, выполненных по нажатию клавиши "Walk". Это и есть содержимое объектов, находящихся в выбранной подветви. Ниже всех находится группа полей ввода, обеспечивающая возможность изменения данных, находящихся внутри выбранного объекта. Впрочем, есть возможность редактировать и любой другой объект, к которому есть доступ Read-Write. Для это нужно изменить OID, установленный по умолчанию в строке редактирования. После того, как все необходимые данные введены в поля редактирования, жмем кнопку "Set" и смотрим на результат. Отсюда следует вывод, что мы можем не только просматривать данные, но и довольно легко редактировать их. Спору нет, все возможности, предоставленные нам программой GetIf, очень даже полезны, но кое-что все же нужно улучшить. Например, расширить базу MIB, которую она использует, потому что в комплекте MIB поставляемом по умолчанию не хватает многих жизненно важных OID. Берем архив необходимых нам MIB здесь http://www.wtcs.org/snmp4tpc/FILES/Tools/SNMP/getif/GETIF-MIBS.ZIP. Распаковываем его во временную директорию, затем все файлы с расширением .mib копируем в папку, где у нас установлена программа GetIf. Обычно это C:/Program Files/GetIf 2.2/Mibs/. После копирования удаляем файл .index, содержащий внутри себя список файлов, в которых находятся MIB. Запускаем Getif, файл .index будет создан заново и заполнен новым списком MIB файлов автоматически. Посмотрев на вкладку MBrowser, осознаем сколько полезного добавилось в нашу базу. Если же такое обилие Вас пугает, то можно ограничиться копированием только следующих:
Порыскав несколько минут по дереву, находим OID, содержащий данные о загрузке процессора.
.iso.org.dod.internet.mgmt.mib-2.host.hrDevice.hrProcessorTable.hrProcessorEntry.hrProcessorLoad
К сожалению, данные, предоставляемые Windows для доступа через SNMP, все еще слишком скудны. Хотелось бы иметь более информативную картину процессов, происходящих внутри подопытной машины. Очень хочется, чтобы данные счетчиков производительности (performance counters), о которых шла речь в первой части этой статьи, были доступны нам через SNMP. Добиться подобного приятного эффекта можно с помощью программы, называемой SNMP4W2K. Для Windows NT, соответственно, она будет называться SNMP4NT. Все семейство вышеописанных программ распространяется в двух вариантах. Бесплатная стандартная версия называется SNMP4W2K-STD и SNMP4NT-STD. Соответственно, платная версия зовется SNMP4W2K-PLUS и SNMP4NT-PLUS. В связи с падением спроса на саму Windows NT ,а затем и на платную версию SNMP4NT-PLUS, автор недавно выложил ее в свободный доступ. Нынче вне зависимости от толщины кошелька ее могут скачать все желающие. Разница между версиями состоит в размерах базы MIB и стоимости 50$ за одну лицензию. Бесплатная версия, кроме большого количества стандартных счетчиков, содержит еще и счетчики следующих сервисов Windows:
Платная версия добавляет возможность работать со счетчиками, в которых содержатся данные следующих служб:
Лично мне хватает данных, предоставляемых стандартной версией, поэтому я буду использовать именно ее. Скачиваем отсюда дистрибутив SNMP4W2K. Подробнее ознакомиться с теорией функционирования пакета, почитать список часто задаваемых вопросов и взять версию для Window NT можно на сайте автора http://www.wtcs.org/snmp4tpc/. Ну а сейчас давайте кратко разберемся с вопросами "почему" и "как это работает".
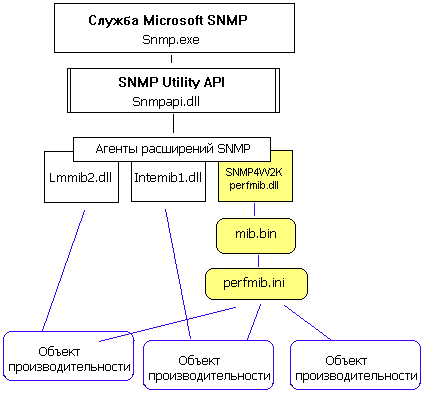
Используя интерфейс расширения агентов SNMP, мы внедряем в Windows свой нестандартный обработчик SNMP perfmib.dll, который, опираясь на базу mib.bin и конфигурацию, сохраненную в файле perfmib.ini, позволяет нам получить доступ к объектам производительности. Соответствие между объектами производительности и OID хранится в базе mib.bin. Распаковав дистрибутив, приступим с нетерпением к инсталляции программы SNMP4W2K-STD. Запускаем файл SNMP4W2K-STD.exe. Согласившись с условиями лицензии, выбираем директорию для инсталляции C:\Program Files\SNMP4W2K-STD\. Как только полоса копирования файлов перестанет мелькать, нам будет предложено две опции "View Readme File" и "Run Installed Application". Недрогнувшей рукой отключаем первую опцию и нажимаем "ОК". После этого появится окно командного интерпретатора с несколькими вопросами, которые нужно уточнить. Соглашаясь с выбором, предлагаемым по умолчанию, нужно будет нажать несколько раз клавишу "Y". Программа инсталляции самостоятельно внесет изменения в реестр и перезапустит службу SNMP. Если браузер SNMP работает, закрываем его. Для того, чтобы новые ветви, добавленные SNMP4W2K, появились в GetIf, нужно скопировать MIB файлы программы SNMP4W2K, находящиеся в директории C:\Program Files\SNMP4W2K-STD\Mibs\ в директорию, где лежат базы MIB нашего браузера C:\Program Files\Getif 2.2\Mibs\. Снова удаляем файл .index и, запустив GetIf, идем любоваться веткой .iso.org.dod.internet.private.enterprises. Все подветви, находящиеся внутри нее, появились благодаря SNMP4W2K. Стоит обратить внимание на один побочный эффект SNMP4W2K. Например, если вы хотите работать с данными сервиса или программы, доступными только через SNMP4W2K, то вам нужно сначала установить саму программу и только затем ставить SNMP4W2K. Яркий пример такого подхода - служба IIS. Если она установлена после SNMP4W2K, то совокупность OID, дающих доступ к ее внутренним данным, работать не будет, потому что SNMP4W2K в момент инсталляции не нашел на машине службу IIS, а значит решил, что захламлять машину лишними MIB не стоит. Если же поступить наоборот - сначала установить IIS, а затем SNMP4W2K, то все будет работать как положено. За решением этой проблемы можно увлекательно потерять не один час рабочего времени. Вот такой вот образец чрезмерной самостоятельности программы SNMP4W2K.
Так как на моей машине нет сервисов вроде WINS, SMTP, DNS то большинство полезной для наблюдения информации находится в объектах ветви .iso.org.dod.internet.private.enterprises.microsoft.software.systems.os.windowsNT.performance.
Давайте определимся, какие OID мы будем использовать для сбора необходимых нам данных. К примеру, загрузку процессора можно узнать с помощью такого OID: .iso.org.dod.internet.private.enterprises.microsoft.software.systems.os.windowsNT.performance.cpuprocessorTable.cpuprocessorEntry.cpuPercentProcessorTime.
К сожалению, процесс использования SNMP не так уж и прост. Для того, чтобы увидеть количество занятой виртуальной памяти, нам придется провести некоторые расчеты. Берем содержимое OID .iso.org.dod.internet.private.enterprises.microsoft.software.systems.os.windowsNT.performance.memmory.memmoryCommitLimit, соответствующее системному счетчику "\Память\Предел выделенной виртуальной памяти", делим его на 100 и получаем величину, показывающую, сколько байт принимается за один процент памяти. В моем случае получилась величина 3.184.967 байт. Отсюда следует вывод, что на моей машине один процент это почти три мегабайта памяти. Получаем данные о количестве израсходованной памяти .iso.org.dod.internet.private.enterprises.microsoft.software.systems.os.windowsNT.performance.memmory.memmoryCommittedBytes, соответствующие счетчику "\Память\Байт выделенной виртуальной памяти". В моей системе это 53776337 байт. Делим полученную величину на размер одного процента, равного 3184967 байт, и получаем 16.88%. Значит, свободной памяти еще достаточно. Именно такую методику расчетов мы будем использовать при настройке порогов критического состояния 90% - 286647030 байт и уровня предупреждения 80% - 254797360 байт для сервиса, с помощью которого Nagios будет следить за потреблением памяти.
Следующий ресурс, за которым нужно следить - свободное место на жестких дисках Windows машины. К сожалению, мне так и не удалось заставить работать ветки .iso.org.dod.internet.private.enterprises.microsoft.software.systems.os.windowsNT.performance.pdiskphysicalDiskTable и .iso.org.dod.internet.private.enterprises.microsoft.software.systems.os.windowsNT.performance.ldisklogicalDiskTable, отвечающие за физические устройства жестких дисков и логические тома файловых систем. Но огорчаться по этому поводу не стоит. Вместо OID, созданных SNMP4W2K, мы будем использовать стандартную ветвь .iso.org.dod.internet.mgmt.mib-2.host.hrStorage.hrStorageTable. Первым делом обращаемся к ветке .iso.org.dod.internet.mgmt.mib-2.host.hrStorage.hrStorageTable.hrStorageEntry.hrStorageDescr чтобы узнать, какое из устройств нас интересует. Используя OID hrStorageDescr, читаем текстовое описание объектов, содержащихся внутри массива, прикрепленного к этой ветке.
| Имя объекта | Содержимое |
| hrStorageDescr.1 | A:\ |
| hrStorageDescr.2 | C:\ Label: Serial Number 445c03ba |
| hrStorageDescr.3 | D:\ |
| hrStorageDescr.4 | Virtual Memory |
Как мы видим, объект номер 1 - это дисковод гибких дисков, а номера 2 и 3 - соответственно, C:\ - жесткий диск и D:\ - CD-ROM. Также интересен номер 4, представляющий объект, содержащий данные о количестве доступной виртуальной памяти. Идем по нашему массиву дальше и обращаемся к OID hrStorageAllocationUnits, описывающему размер в байтах одного блока памяти каждого из вышеназванных устройств.
| Имя объекта | Содержимое |
| hrStorageAllocationUnits.1 | 0 |
| hrStorageAllocationUnits.2 | 2048 |
| hrStorageAllocationUnits.3 | 0 |
| hrStorageAllocationUnits.4 | 65536 |
Опираясь на таблицу приведенныу выше можно сделать вывод что, размер блока для диска C:\ равен 2048 байтам, а для виртуальной памяти соответствует 65536 байт. Теперь нужно узнать общий размер памяти каждого из перечисленных устройств, используя OID hrStorageSize.
| Имя объекта | Содержимое |
| hrStorageSize.1 | 0 |
| hrStorageSize.2 | 1044209 |
| hrStorageSize.3 | 0 |
| hrStorageSize.4 | 4859 |
Стоит отметить, что размер считается в блоках, о которых мы говорили ранее. Значит, чтобы узнать размер диска C:\ в байтах, умножаем hrStorageAllocationUnits.2 на hrStorageSize.2 и в результате всех этих вычислений получаем цифру, примерно равную двум гигабайтам. Таким же способом вычисляем размер виртуальной памяти и получаем 318439424 байта. Теперь внимание, подходим к самому главному. Данные о том, сколько памяти уже израсходовано, находятся внутри hrStorageUsed.
| Имя объекта | Содержимое |
| hrStorageUsed.1 | 0 |
| hrStorageUsed.2 | 418859 |
| hrStorageUsed.3 | 0 |
| hrStorageUsed.4 | 0 |
Так как использованное место измеряется опять же в блоках, то переводить его в байты особого смысла нет. Нужного эффекта можно добиться, контролируя процент использования блоков. Догадаться, как узнать, сколько блоков в одном проценте, несложно. Я думаю, вы и сами легко сможете расчитать для диска C:\ порог в 80% и 90% заполнения. Для моей системы это соответственно 835367 и 938788 блоков. При достижении этих значений Nagios должен будет отправлять нам предупреждение.
Еще одним из параметров, за которыми стоит следить, является процент использования файла подкачки. Для этого нам нужно брать данные из объекта с таким именем:
.iso.org.dod.internet.private.enterprises.microsoft.software.systems.os.windowsNT.performance.pagefilepaging-FileTable.pagefilepaging-FileEntry.pagefilePercentUsage
Я думаю, выбранных нами объектов достаточно для надежного мониторинга. По своему усмотрению вы можете добавить любые другие объекты к этому списку. У вас, например, могут работать службы, которые на моей тестовой машине отсутствуют. Благо, количество данных, хранящихся в базе MIB позволяет, собирать очень подробную статистику.
Завершив работу с Windows, переходим к FreeBSD. Для получения данных через SNMP Nagios использует модуль check_snmp. Ну а тот, в свою очередь, опирается на пакет программ net-snmp, предназначенный для работы с протоколом SNMP. Многим из администраторов этот пакет известен под старым названием ucd-snmp. Вы можете использовать либо ucd-snmp, либо net-snmp. Я же по своей давно укоренившейся привычке стараюсь использовать новейшее из доступного на данный момент программного обеспечения. Поэтому, выбрав net-snmp, скачиваю самую последнюю версию пакета отсюда http://net-snmp.sourceforge.net/. На момент написания статьи это была версия 5.0.8. Распаковываю архив исходного кода и начинаю установку.
# tar zxvf net-snmp-5.0.8.tar.gz
После того, как я запустил скрипт configure, на экране появилось несколько вопросов, на которые обязательно нужно дать ответ.
# ./configure Defaul version of SNMP to use (3): 3 # Версия протокола SNMP, которую надлежит использовать по умолчанию #для всех запросов. # Можно написать 1, 2c, 3. Я, как всегда, выбрал самую новую. System contact infomation root@: tigrisha@sysadmins.ru # Адрес лица, ответственного за работу SNMP. Можно писать что угодно. System Location (Unknown): home # Географическое местоположение этой машины. Снова можно писать все, что # придет в голову. Location to write log file /var/log/snmpd.log: /var/log/snmpd.log # Сюда демон snmpd будет записывать файлы журналов своей работы Location to write persistent information /var/net/snmp: /var/net/snmp # А тут подсистема SNMP будет хранить свою рабочую информацию
Убедившись в том, что скрипт configure завершил работу без ошибок, начинаем сборку.
# make
Затем, задав с помощью команды umask права на все вновь создаваемые файлы, проводим инсталляцию.
# umask 022 # make install
Все выполняемые файлы программ из этого пакета устанавливаются в /usr/local/bin/. Этот факт желательно запомнить, потому что в будущем подобные знания нам очень пригодятся. По завершении установки в /usr/local/bin появятся следующие утилиты для работы с SNMP:
snmpbulkget snmpbulkwalk snmpcheck snmpconf snmpdelta snmpdf snmpget snmpget.old snmpgetnext snmpinform snmpnetstat snmpset snmpstatus snmptable snmptest snmptranslate snmptrap snmpusm snmpvacm snmpwalk
Не стоит отчаиваться, если процедура инсталляции по каким-либо причинам у вас не сработает. Net-snmp, как и ucd-snmp, можно установить из портов или пакетов, поставляющихся вместе с FreeBSD. Например, в дистрибутиве FreeBSD 4.7, на которой работает описываемая система, обе вышеназванных программы можно получить с 4-го диска, содержащего коллекцию пакетов. Оба упомянутых пакета находятся внутри ветки Net. Я надеюсь, вы умеете самостоятельно устанавливать программы из портов или пакетов. Если брать программы из этой коллекции, то мы можем стать обладателями довольно свежих экземпляров net-snmp версии 5.0.3_2 или ucd-snmp версии 4.2.5_2. Каким путем пойти, оставляю полностью на ваше усмотрение. Все три способа установки проверены мною лично. Могу сказать, что они работает нормально, и наступить на грабли можно только при фатальном невезении.
После инсталляции нужно провести некоторые действия, необходимые для более безопасной работы сервера мониторинга. В комплекте обоих вышеперечисленных программ поставляется демон SNMP. Несмотря на все свои достоинства, этот демон нам не нужен, так как наша FreeBSD машина не будет принимать входящие SNMP запросы. Для того, чтобы создавать исходящие запросы, его функциональность тоже не требуется. Опираясь на эти умозаключения, сначала останавливаем, а затем и полностью отключаем демона snmpd. Для отключения нужно снять атрибут выполнения со скрипта /usr/local/etc/rc.d/snmpd.sh, запускающего демона после каждой перезагрузки системы.
# /usr/local/etc/rc.d/snmpd.sh stop # chmod ugo-x /usr/local/etc/rc.d/snmpd.sh
Я надеюсь, что все помнят: подключаемые модули Nagios находятся в пакете nagios-plugins. Я использовал версию 1.3.0 - beta 3. Несмотря на то, что этот пакет у вас скорее всего уже установлен, модуля check_snmp в директории /usr/local/libexec/ скорее всего нет. Такой поворот событий встречается довольно часто. А произошло это потому, что на машину сначала был установлен nagios-plugins и только затем одна из версий snmp. Скрипт configure, выполняемый перед компиляцией модулей, пытаясь удовлетворить все зависимости, запрашиваемые пакетом,. не нашел на вашей машине ни ucd-snmp ни net-snmp. Значит, нам нужно сконфигурировать пакет nagios-plugins заново. После распаковки переходим в каталог с исходными текстами nagios-plugins и выполняем следующие команды:
# ./configure --prefix=/usr/local/nagios --with-nagios-user=nagios --with-nagios-grp=nagios # gmake all # gmake install
Разобравшись с первоначальной настройкой, приступим к изучению того, как это работает. Для сбора данных модуль check_snmp использует программу snmpget. Давайте попробуем выполнить из командной строки проверку времени работы Windows машины с момента последней перезагрузки.
#/usr/local/nagios/libexec/check_snmp -H win2000rus -C QWEmn90 -o system.sysUpTime.0 SNMP problem - No data recieved from host CMD: /usr/local/bin/snmpget -m ALL -v 1 -c QWEmn90 win2000rus system.sysUpTime.0
Получив ошибку, не огорчаемся, а читаем статью дальше. Поняв механизмы действия модуля, мы сможем починить его самостоятельно. Итак, давайте окунемся с головой в теорию функционирования модуля check_snmp. При каждом запуске check_snmp создает дочерний процесс snmpget, которому передаются следующие параметры запроса.
-v 1
# Версия протокола. Windows поддерживает версии 1 и 2c. Лучше использовать 2с ,
# потому что версия 1 небезопасна.
-m ALL
# Приказываем использовать все имеющиеся файлы MIB
-c QWEmn90
# Имя сообщества, используемое для доступа к данным. Позволяет только чтение.
win2000rus
# Имя или IP адрес машины, которой нужно отправить запрос.
OID
# Идентификатор объекта, в котором находятся интересующие нас данные.
В свою очередь, результаты работы snmpget обрабатываются check_snmp и передаются Nagios. Вот тут нас поджидают две ловушки. Проблема первая состоит в том, что формат вызова snmpget зависит от того, из какого пакета производилась установка средств для работы с SNMP.
Рассмотрим различия на примере команды, которая должна получить с удаленной машины время работы системы.
Версия net-snmp:
# /usr/local/bin/snmpget -v2c -m ALL -c QWEmn90 win2000rus system.sysUpTime.0
Версия ucd-snmp:
# /usr/local/bin/snmpget -m ALL -c QWEmn90 -v2c win2000rus system.sysUpTime.0
Выполните обе команды и, в зависимости от версии SNMP программ, полюбуйтесь на появившиеся ошибки. Вторая проблема состоит в том, что snmpget упрямо не хочет работать с OID, созданными SNMP4W2K и SNMP4NT. К примеру, попробуйте выполнить два разных варианта команды, получающей с удаленной машины данные о загрузке процессора. Обратите внимание, OID для краткости записан в цифровом виде.
Версия net-snmp:
# /usr/local/bin/snmpget -v2c -m ALL -c QWEmn90 win2000rus .1.3.6.1.4.1.311.1.1.3.1.1.2.1.3.1
Версия ucd-snmp:
# /usr/local/bin/snmpget -m ALL -c QWEmn90 -v2c win2000rus .1.3.6.1.4.1.311.1.1.3.1.1.2.1.3.1
Казалось бы, вид ошибок, полученных в ответ на команды, должен повергнуть нас в жесточайшее разочарование. Но не тут то было. Вместо snmpget мы станем использовать программу snmpwalk, которая гораздо стабильнее работает с нестандартными OID. Итак, переделываем наши команды и снова радуемся жизни.
Версия net-snmp:
# /usr/local/bin/snmpwalk -v2c -m ALL -c QWEmn90 win2000rus .1.3.6.1.4.1.311.1.1.3.1.1.2.1.3.1
Версия ucd-snmp:
# /usr/local/bin/snmpwalk -m ALL -c QWEmn90 -v2c win2000rus .1.3.6.1.4.1.311.1.1.3.1.1.2.1.3.1
Разобравшись с этими мелкими проблемами, переходим к работе по исправлению модуля check_snmp. Идем в директорию plugins и открываем на редактирование файл исходного кода check_snmp.c. Ищем в нем вот такой фрагмент текста, отвечающий за вызов команды snmp_get:
/* create the command line to execute */ command_line = ssprintf (command_line, "%s -m ALL -v 1 %s %s %s", PATH_TO_SNMPGET, server_address, community, oid);
Найдя нужный фрагмент, заменяем его на вариант для своей версии пакета snmp.
Версия net-snmp:
/* create the command line to execute */ command_line = ssprintf (command_line, "%s -v2c -m ALL -c %s %s %s", "/usr/local/bin/snmpwalk",community ,server_address , oid);
Версия ucd-snmp:
/* create the command line to execute */ command_line = ssprintf (command_line, "%s -m ALL -c %s -v2c %s %s", "/usr/local/bin/snmpwalk", community, server_address, oid);
Сохранившись, выходим и запускаем повторно компиляцию, а затем уже и инсталляцию.
# gmake all # gmake install
Теперь пришло время снова проверить работоспособность модуля check_snmp. Для этого мы попытаемся получить многократно упоминаемые ранее данные о загрузке процессора Windows машины. Заодно узнаем, насколько правильно работает OID из коллекции SNMP4W2K
#/usr/local/nagios/libexec/check_snmp -H win2000rus -C QWEmn90 -o .1.3.6.1.4.1.311.1.1.3.1.1.2.1.3.1 SNMP OK - INTEGER: 12
Судя по полученному ответу, модуль наконец-то заработал как положено. Загрузка процессора равна 12 процентам, что в общем очень даже неплохо.
Теперь приступим к настройке самого Nagios. Первым делом в файле checkcommands.cfg нам нужно определить команду check_snmp_oid, которую мы будем использовать для сбора данных.
define command{ command_name check_snmp_oid command_line $USER1$/check_snmp -H $HOSTADDRESS$ -o $ARG1$ -C $ARG2$ -w $ARG3$ -c $ARG4$ -u $ARG5$ -l "" }
Давайте разберемся со значением макросов, передаваемых команде check_snmp.
Обратите внимание на опцию -l "" . Она позволяет заменить строку, добавляющую в результат статус snmp запроса. Обычно статус выглядит так "SNMP OK". Мне эта строка показалась лишней, поэтому я заменяю ее пустотой.
В дальнейшем я предполагаю, что вы, прочитав первую часть статьи, внесли все необходимые для работы с машиной win2000rus данные в файлы hosts.cfg, hostgroups.cfg, поэтому говорить о них мы не будем. Разобравшись с определением команд, переходим к описанию тестируемых сервисов.
# Сервис, показывающий данные о проценте использования файла подкачки
define service{
use generic-service
host_name win2000rus
service_description SNMP Page File Usage
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Порог предупреждения устанавливаем на 80%, а критическое состояние на 90%
# Обратите внимание на знак "%", передаваемый в последнем аргументе.
# Мы присоединяем этот знак к результатам, возвращаемым после
# выполнения запроса.
check_command check_snmp_oid!.1.3.6.1.4.1.311.1.1.3.1.1.6.1.3!QWEmn90!80!90!%
}
# Данные о загрузке процессора, собираемые через SNMP4W2K
define service{
use generic-service
host_name win2000rus
service_description SNMP CPU Load
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
check_command check_snmp_oid!.1.3.6.1.4.1.311.1.1.3.1.1.2.1.3.1!QWEmn90!80!90!%
}
# Данные о загрузке процессора, собираемые через стандартную ветку
# .iso.org.dod.internet.mgmt.mib-2.host.hrDevice.hrProcessorTable.hrProcessorEntry.hrProcessorLoad
define service{
use generic-service
host_name win2000rus
service_description SNMP hrProcessorLoad
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
check_command check_snmp_oid!.1.3.6.1.2.1.25.3.3.1.2.2!QWEmn90!80!90!%
}
# Время работы системы с момента последней перезагрузки
define service{
use generic-service
host_name win2000rus
service_description SNMP Up Time
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Обратите внимание на то, что пороги предупреждения и
# критического состояния для данного сервиса смысла не
# имеют, поэтому отключены с помошью пустых кавычек "".
# Дописывать в результат тоже ничего не будем, а значит
# снова нужно использовать ""
check_command check_snmp_oid!.1.3.6.1.2.1.1.3!QWEmn90!""!""!""
}
# Процент использования виртуальной памяти
define service{
use generic-service
host_name win2000rus
service_description SNMP Virtual Memory usage
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
check_command
# Порог предупреждения устанавливаем на достижении 80% заполнения,
# соответствующих 254797360 байтам, и критическое состояние,
# наступающее при заполнении 90% памяти, устанавливаем на отметку в
# 286647030 байт.
# В результат, возвращаемый модулем, добавляем строку "bytes"
check_snmp_oid!.1.3.6.1.4.1.311.1.1.3.1.1.1.3.0!QWEmn90!254797360!286647030!bytes
}
# Сколько места израсходовано на диске C:\
define service{
use generic-service
host_name win2000rus
service_description SNMP Space used on disk C:\
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 1
retry_check_interval 1
contact_groups win-admins
notification_interval 120
notification_period 24x7
notification_options c,r
# Порог предупреждения наступает при расходе 80% пространства диска -
# соответственно, 835367 блока.
# Критическое состояние наступает при заполнении 90% пространства.
# Для моей машины это 938788 блоков.
# В отчет, возвращаемый модулем, добавляем строку "blocks"
check_command check_snmp_oid!.1.3.6.1.2.1.25.2.3.1.6.2!QWEmn90!835367!938788!blocks
}
Теперь, когда с настройкой закончено, заставляем Nagios загрузить обновленные файлы конфигурации.
# /usr/local/etc/rc.d/nagios
Если ошибок не возникло, то немножко радуемся и приступаем к созданию критических ситуаций на Windows машине. Проведя полное стрессовое тестирование системы, понимаем, что теперь ни один сбой системы не застанет нас врасплох. В заключение статьи хотелось бы сказать, что SNMP4W2K позволяет следить за гораздо большим набором показателей здоровья сервера и служб, работающих под управлением Windows, чем я смог описать в этой статье. Я думаю, после такого продолжительного, но, надеюсь, увлекательного обучения каждый из вас сможет воспользоваться всей мощью, предоставляемой SNMP.