| Каталог документации / Раздел "Программирование, языки" / Оглавление документа |
| |
В этой главе мы коснемся проблем интернационализации приложений, написаных с помощью библиотеки Qt. Первый раздел полностью посвящен Unicode -- кодировке символов, принятой в Qt. Сведения, которые содержатся в этом разделе, будут полезны всем Qt-разработчикам, поскольку даже если приложение разрабатывалось исключительно с англоязычным интерфейсом, рано или поздно оно может оказаться запущенным на машине грека или японца.
Во втором разделе будет показано, как разрабатывать приложения, которые потом можно будет перевести на другие языки. Этот процесс настолько прост, что не стоит отказываться от такой возможности, даже если вы не планируете выпускать локализованные версии приложения.
В третьем разделе будет рассказываться об истинно интернациональных приложениях. Здесь же мы покажем, как изменить язык интерфейса прямо во время исполнения приложения.
В последнем разделе мы опишем процесс перевода приложений на другие языки. А так же покажем, как программист и переводчик могут совместно работать над проектом, пользуясь утилитой Qt Linguist и другим инструментарием.
Unicode -- это стандарт кодировки символов, который поддерживает большинство систем записи символов. Первоначально, идея Unicode состояла в том. чтобы каждый из символов кодировался не 8-ю, а 16-ю битами, что дает возможность определить 65536 символов, вместо 256. Наборы символов ASCII и ISO 8859-1 (Latin-1) являются поднаборами Unicode, и сохранили числовые значения своих символов. Например, Символ 'A' имеет значение 0x41 в ASCII, Latin-1 и Unicode.
Класс QString хранит строки как Unicode. Каждый символ в QString является 16-ти битным QChar, а не 8-ми битным char. Ниже приводится два способа записи символа 'A' в строку:
str[0] = 'A';
str[0] = QChar(0x41);
Мы можем записать любой из символов Unicode, по его числовому
значению. Например, так можно записать символ греческого алфавита
('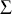 ') и знак евро ('
') и знак евро (' ')
')
str[0] = QChar(0x3A3);
str[0] = QChar(0x20AC);
Числовые значения всех символов Unicode вы найдете по адресу
http://www.unicode.org/unicode/standard/standard.html.
Если у вас не возникает необходимости использовать не
Latin-1 символы, вам достаточно будет ознакомиться с кодами
символов в общих чертах. С другой стороны Qt предлагает
более удобный способ ввода символов Unicode в программах,
как -- будет описано немного ниже.Текстовый движок Qt 3.2 поддерживает следующие наборы символов на всех платформах: Арабский, Китайский, Кириллический, Греческий, Иврит, Японский, Корейский, Лао, Латинский, Тайский и Вьетнамский. Кроме этого, на платформах X11 с Xft и Windows NT, дополнительно поддерживаются следующие наборы символов: Бенгальский, Девангари, Гуджарати, Каннада, Кхмерский, Сирийский, Тамильский, Телугу и Тана. На X11 поддерживаются еще Малайский и Тибетский наборы символов, а на Windows XP дополнительно поддерживается Дивехи. Если исходить из предположения, что в системе установлены соответствующие шрифты, Qt будет в состоянии отображать все символы из этих наборов.
Принципы работы с QChar, в программах, несколько отличается от принципов работы с char. Чтобы получить числовое значение символа QChar, нужно вызвать метод этого класса unicode(). Чтобы получить код символа ASCII или Latin-1, класса QChar нужно вызвать метод этого класса latin1(). Если символ не относится к поднабору Latin-1, latin1() вернет 0.
Если заранее известно, что программа будет работать исключительно с символами ASCII или Latin-1, можно использовать функции из <cctype>, такие как: isalpha(), isdigit() и isspace(). Они будут работать безотказно, потому что символы QChar автоматически преобразуются в char, в данном контексте, так же как и QString автоматически преобразуется в const char *. Однако, в любом случае лучше пользоваться функциями-членами класса QChar, для выполнения подобных операций, поскольку они будут корректно работать с любыми символами Unicode. Среди функций, которые предоставляются классом QChar, можно назвать: isPrint(), isPunct(), isSpace(), isMark(), isLetter(), isNumber(), isLetterOrNumber(), isDigit(), isSymbol(), lower() и upper(). Например, так можно проверить -- является ли символ цифрой или символом верхнего регистра:
if (ch.isDigit() || ch != ch.lower())
...
Функция lower() возвращает версию
символа в нижнем регистре. Если результат функции отличается от
оригинального символа, значит это символ верхнего регистра (или
заглавный символ). Этот отрывок кода справедлив для языков, которые
различают регистр символов (прописные и строчные), включая латиницу,
кириллицу и набор греческих символов.Как только мы начинаем работать с Unicode-строками, у нас появляется возможность использовать их повсюду, где Qt API ожидает получить QString. В свою очередь, Qt берет на себя ответственность по корректному отображению символов строки и преобразованию в другие кодировки, если в этом возникает необходимость.
Особую осторожность нужно проявлять при работе с текстовыми файлами. Они могут содержать текст в самых разнообразных кодировках, определить которую, зачастую практически невозможно. По-умолчанию QTextStream использует системную 8-ми битную кодировку символов (QTextCodec::codecForLocale()), как для записи, так и для чтения файлов.
Если у вас есть желание писать в файлы любые Unicode символы, можно предложить сохранять данные как Unicode, для этого, непосредственно перед записью данных, с помощью QTextStream, нужно вызвать функцию setEncoding(QTextStream::Unicode). В результате текст будет записан в файл в кодировке UTF-16, где каждый символ представлен двумя байтами. Формат UTF-16 очень близок к представлению QString в памяти, поэтому чтение/запись строк UTF-16 выполняется очень быстро. Однако, этот формат довольно расточителен в случае символов ASCII, для хранения которых достаточно одного байта.
При чтении данных из файла, QTextStream обычно автоматически определяет Unicode, но для полной уверенности, перед выполнением процедуры чтения, лучше все-таки вызвать setEncoding(QTextStream::Unicode).
Еще одна кодировка, которая поддерживает весь набор символов Unicode -- это UTF-8. Ее основное преимущество перед UTF-16 состоит в том, что для хранения символов ASCII (символы в диапазоне 0x00..0x7F) она использует всего один байт. Все остальные символы, включая символы Latin-1, числовые значения которых лежат выше 0x7F, представлены многобайтными последовательностями. Для хранения текста, состоящего преимущественно из ASCII-символов, в формате UTF-8 потребуется практически в два раза меньше пространства, чем в UTF-16. Чтобы использовать для записи/чтения текстовых файлов формат UTF-8, предварительно нужно вызвать setEncoding(QTextStream::UnicodeUTF8).
Если предполагается использование исключительно кодировки Latin-1, вне зависимости от настроек локали пользователя, можно вызвать setEncoding(QTextStream::Latin1).
Другие виды кодировки могут быть установлены с помощью вызова функции setCodec(), передав ей соответствующий QTextCodec. Класс QTextCodec выполняет преобразование между Unicode и заданной кодировкой. Экземпляры этого класса очень широко используются в библиотеке Qt. Они используются для поддержки шрифтов, методов ввода, буфера обмена, механизма "drag-and-drop" и именования файлов.
Рассмотрим такой пример: допустим, что нам необходимо прочитать файл, записанный в кодировке EUC-KR, тогда мы могли бы написать такой код:
QTextStream in(&file);
QTextCodec *koreanCodec = QTextCodec::codecForName("EUC-KR");
if (koreanCodec)
in.setCodec(koreanCodec);
Некоторые форматы файлов могут содержать указание о кодировке
символов в области заголовка. В данном случае, заголовок -- это некая
область в начале файла, которая содержит исключительно ASCII-символы,
чтобы иметь гарантированную возможность их чтения, независимо от
настроек локали. Наиболее типичный пример -- файлы формата XML,
которые, как правило, используют кодировку UTF-8 или UTF-16. Самый
правильный способ настройки QTextStream,
перед работой с XML-файлами, это вызвать setEncoding(QTextStream::UnicodeUTF8). Если файл
ранее был сохранен в UTF-16, QTextStream
автоматически определит это обстоятельство и скорректирует свои
настройки. Заголовок XML-файла, иногда может содержать описание
кодировки в заголовке <?xml?>
(аргумент encoding), например:
<?xml version="1.0" encoding="EUC-KR"?>
Поскольку QTextStream не допускает
изменения настройки кодировки после начала процедуры чтения, то
наиболее правильный подход заключается в том, чтобы начать чтение файла
заново, после того как будет задана правильная кодировка (может быть
получена с помощью QTextCodec::codecForName()).Но не стоит забывать, что в случае XML, мы можем использовать специализированные классы Qt, предназначенные для работы с данными файлами (см. Главу 14), что избавит нас от необходимости беспокоиться о кодировке файлов.
Еще одна область применения QTextCodec -- задание кодировки для строк, размещаемых в исходном тексте программ. Рассмотрим такой пример: группа японских программистов разрабатывают приложение, предназначенное, в первую очередь, для внутреннего рынка. Наиболее вероятно, что исходные тексты набираются в редакторе, в кодировке EUC-JP или Shift-JIS, что позволяет им вставлять японские иероглифы прямо в текст программы, примерно так:
QPushButton *button = new QPushButton(tr(" "), 0);
"), 0);
По-умолчанию, Qt интерпретирует аргументы функции
tr() как Latin-1. Чтобы установить
иную кодировку, нужно вызвать статическую функцию QTextCodec::setCodecForTr(), например:
QTextCodec *japaneseCodec = QTextCodec::codecForName("EUC-JP");
QTextCodec::setCodecForTr(japaneseCodec);
Это должно быть сделано перед самым первым вызовом функции
tr(). Как правило это делается в функции
main(), после создания объекта
QApplication.Но все остальные строки в программе, по прежнему будут интерпретироваться как Latin-1. Если программист хочет записать японские иероглифы в строковую переменную, он должен выполнить явное преобразование в Unicode:
QString text = japaneseCodec->toUnicode(" ");
");
Как альтернатива -- установить соответствующий кодек для
выполнения преобразований между const char *
и QString, вызовом
QTextCodec::setCodecForCStrings():
QTextCodec::setCodecForCStrings(japaneseCodec);
Техника, описанная выше, может применяться к любой кодировке, не
являющейся Latin-1, включая Китайскую, Греческую, Корейскую и Русскую.
Ниже приводится список кодировок, поддерживаемых библиотекой Qt 3.2:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Пред. | В начало | След. |
| Запись в XML-документы. | На уровень выше | Разработка приложений, подготовленных к переводу. |



|
Закладки на сайте Проследить за страницей |
Created 1996-2026 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |